CCI 3.0是智源研究院推出的一个庞大的中文互联网语料库,涵盖了1000GB的数据集以及498GB的高质量子集CCI 3.0-HQ。与前一版本CCI 2.0相比,CCI 3.0的数据规模几乎翻了一番,数据来源机构也增至20多家,从而显著提高了数据的覆盖广度和代表性。
CCI 3.0是什么
CCI 3.0是由智源研究院发布的一项大型中文互联网语料库,包含1000GB的总数据集以及498GB的高质量子集CCI 3.0-HQ。相较于CCI 2.0,CCI 3.0在数据规模上几乎翻倍,增加了20多家数据来源机构,极大地拓宽了数据的覆盖面和代表性。该语料库收录了超过2.68亿个网页,涵盖新闻、社交网络、博客等多个领域。CCI 3.0对原始数据进行了详尽的分类和标注,涉及语法、句法、教育背景等多个维度,筛选出高价值的数据。
CCI 3.0的主要功能
- 丰富的数据规模与来源:CCI 3.0的数据量达到1000GB,涵盖了超过2.68亿个网页,内容涉及新闻、社交媒体、博客等多个领域。数据来源机构多达20余家,增强了数据的全面性和代表性。
- 精确的标注体系:CCI 3.0对原始数据进行了细致的分类和标注,涵盖语法、句法、教育程度等十多个维度,以筛选出更具价值的数据。
- 高质量子集:CCI 3.0包括498GB的高质量子集CCI 3.0-HQ,该子集通过70B模型的自动标注和小型质量模型的训练,确保能够满足各种行业和应用的需求。
- 严格的数据处理标准:在构建过程中,CCI 3.0采用了基于规则的过滤(如关键词和垃圾信息过滤)、基于模型的过滤(如低质量内容过滤)等多种方法来确保数据的质量和安全性。
CCI 3.0的技术优势
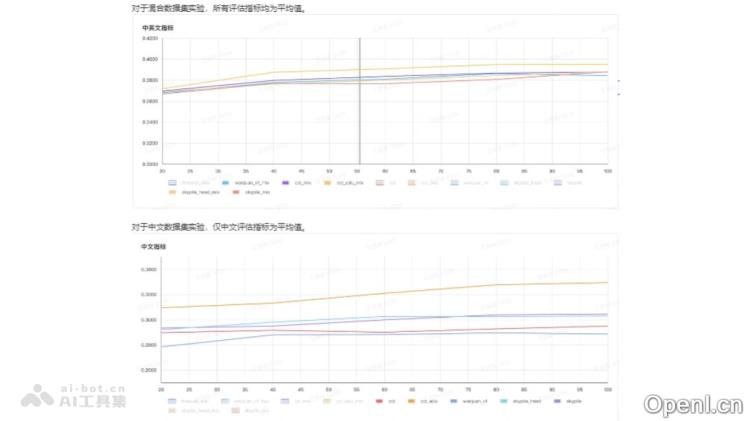
- 卓越的训练效果:对比实验显示,基于不同数据集从零开始训练的100B模型,CCI 3.0在中文语料和中英文混合训练的效果上均优于其他数据集,特别是CCI 3.0 HQ的表现更为突出。
- 共建共享的理念:CCI 3.0的推出推动了数据的共建与共享,旨在构建一个高质量、高知识密度的中文数据集,为中国人工智能行业的发展贡献力量。
- 便捷的获取途径:研究者和开发者可以通过Flopsera、Huggingface以及Datahub等平台轻松下载CCI 3.0的数据集。
CCI 3.0的项目地址
CCI 3.0的应用场景
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。