UniTalker是一款先进的音频驱动3D面部动画生成模型,能够根据输入音频生成自然逼真的面部动作。它采用统一的多头架构,支持多种语言和音频格式的处理,包括语音和歌曲,适用于多种应用场景,如动画制作、虚拟现实和游戏开发。
UniTalker是什么
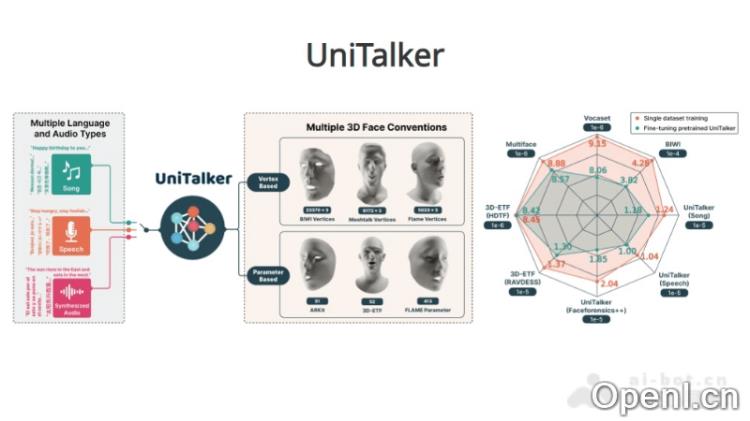
UniTalker是一款创新的音频驱动3D面部动画生成模型,能够根据输入的音频内容生成真实感极强的面部动作。它采用了统一的多头架构,使用带有不同标注的数据集,支持多语言和多种类型的音频处理,包括语音和音乐。无论是清晰的言语还是带有噪音的歌声,UniTalker都能出色地进行处理。此外,UniTalker可以同时为多个角色生成面部动作,灵活性和便利性极高。
UniTalker的主要功能
- 音频驱动的3D面部动画:UniTalker能根据输入音频生成真实的3D面部动作,使虚拟角色的表情和口型与声音完美同步。
- 多语言及多音频支持:处理不同语言的语音和各种音频文件,特别适用于国际化应用场景。
- 统一架构模型:UniTalker基于多头架构设计,能够在同一框架内处理多种不同的数据集和注释类型,提升了模型的灵活性和通用性。
- 训练稳定性与一致性:通过主成分分析(PCA)、模型预热及枢纽身份嵌入等训练策略,UniTalker在训练过程中展现出更高的稳定性,并确保了多头输出的一致性。
UniTalker的技术原理
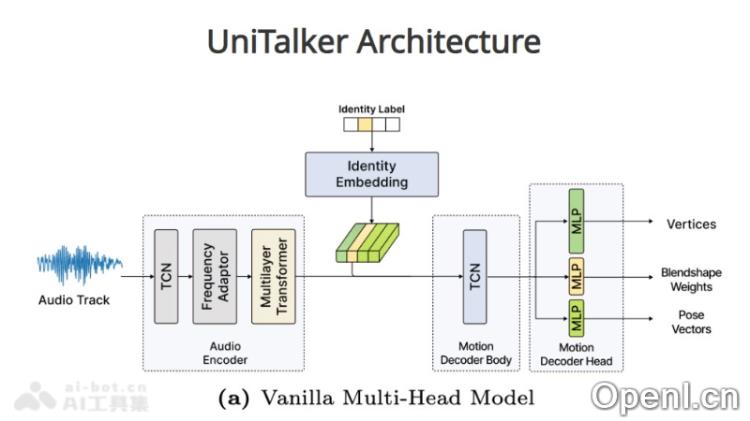
- 多头架构设计:UniTalker采用统一的多头架构,基于多种标注的数据集进行训练,以满足各种3D面部动画需求。
- 训练策略:为提高训练的稳定性及多头输出一致性,UniTalker使用了包括主成分分析(PCA)、模型预热和枢纽身份嵌入的多种训练策略。
- 大规模数据集:研究团队构建了A2F-Bench基准测试,涵盖了五个公开数据集和三个新编制数据集,扩大了训练数据的规模和多样性,涵盖了多种语言的语音和歌曲。
- 音频编码器:UniTalker使用音频编码器将输入音频转化为上下文化的音频特征,为后续面部动作的生成奠定基础。
UniTalker的项目地址
- 项目官网:https://x-niper.github.io/projects/UniTalker/
- GitHub库:https://github.com/X-niper/UniTalker
- arXiv技术论文:https://arxiv.org/pdf/2408.00762
UniTalker的应用场景
- 动画制作:UniTalker能够依据音频生成生动的3D面部动作,为动画角色增添丰富的表情和口型。
- 虚拟现实(VR):在虚拟现实环境中,UniTalker可以根据语音指令生成相应的面部动作,增强沉浸感。
- 游戏开发:UniTalker为游戏中的非玩家角色(NPC)提供自然的面部表情和动作,提升游戏的互动性和真实感。
- 语言学习:UniTalker能够生成特定语言的口型和表情,帮助学习者模仿发音和表情,提升语言学习效果。
- 多语言支持:UniTalker支持多种语言的音频输入,包括中文,适合国际化应用场景。
常见问题
UniTalker可以处理哪些类型的音频? UniTalker支持多种音频格式,包括语音和歌曲,能够根据输入音频生成面部动画。
UniTalker是否支持多语言? 是的,UniTalker可以处理多种语言的音频,适用于国际化场景。
如何访问UniTalker的项目资源? 您可以通过访问项目官网、GitHub库和arXiv技术论文获取相关资源。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。