EchoMimic是阿里蚂蚁集团推出的开源AI数字人项目,通过结合深度学习技术,为静态图像注入生动的声音和表情,创造出高度逼真的动态肖像视频。该项目不仅可以单独使用音频或面部特征生成视频,还能将两者结合,呈现出更加自然流畅的对口型效果。
EchoMimic是什么
EchoMimic是一个前沿的AI数字人开源项目,由阿里蚂蚁集团开发,旨在为静态图像赋予活力和个性。它运用深度学习模型,结合音频信息与面部关键点数据,生成极具真实感的动态肖像视频。支持多种语言(如中文和英语),EchoMimic适用于多种场景,包括唱歌和日常对话,为数字人技术带来了创新的突破,广泛应用于娱乐、教育和虚拟现实等领域。
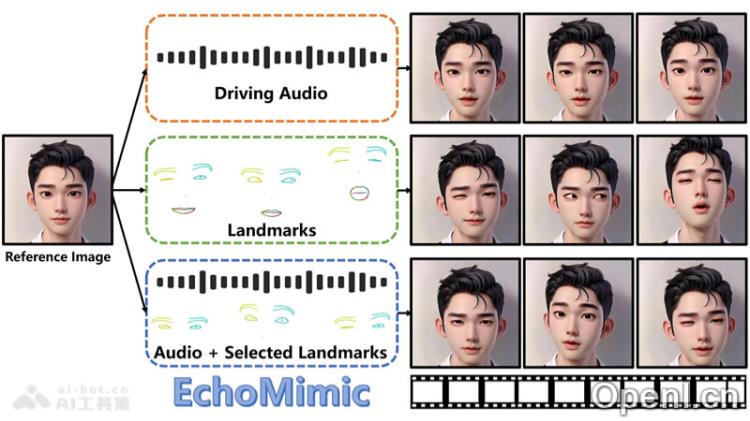
EchoMimic的推出不仅展示了阿里在数字人领域的技术探索,更是对现有技术的一次重大革新。与传统的肖像动画技术相比,EchoMimic通过音频与面部关键点的双重训练,实现了更加自然和真实的动态表现。
主要功能
- 音频同步动画:EchoMimic能够精准分析音频波形,生成与语音同步的口型和表情,为静态图像注入生动的动态表现。
- 面部特征融合:该项目使用面部标志点技术,捕捉眼睛、嘴唇和其他关键部位的,增强了动画的真实感。
- 多模态学习:EchoMimic结合音频和视觉数据,通过多模态学习提升动画的自然度和表现力。
- 跨语言能力:支持中文普通话和英语等多种语言,使不同语言用户均能利用此技术制作动画。
- 风格多样性:EchoMimic适应多种表演风格,包括日常对话和歌唱,为用户提供丰富的应用场景。

产品官网
- 项目官网:https://badtobest.github.io/echomimic.html
- GitHub仓库:https://github.com/BadToBest/EchoMimic
- Hugging Face模型库:https://huggingface.co/BadToBest/EchoMimic
- arXiv技术论文:https://arxiv.org/html/2407.08136
应用场景
EchoMimic的应用场景十分广泛,包括但不限于:
- 娱乐产业:在动画制作、短视频创作等领域,帮助内容创作者提升表现力。
- 教育培训:用于在线教学,增强学习互动性,提高学生的参与感。
- 虚拟现实:为虚拟角色提供生动的表现,提升沉浸感。
- 社交媒体:助力用户创作个性化的动态头像和表情包。
常见问题
- EchoMimic支持哪些语言?:目前支持中文普通话和英语,未来计划扩展更多语言选项。
- 如何使用EchoMimic生成视频?:用户可通过输入音频或上传静态图像,结合EchoMimic的功能轻松生成动态视频。
- EchoMimic的使用是否收费?:作为开源项目,EchoMimic的基础功能可免费使用,但可能存在一些高级功能需付费。
- 我可以将生成的视频用于商业用途吗?:具体使用政策请参考项目官网的相关条款。
技术原理
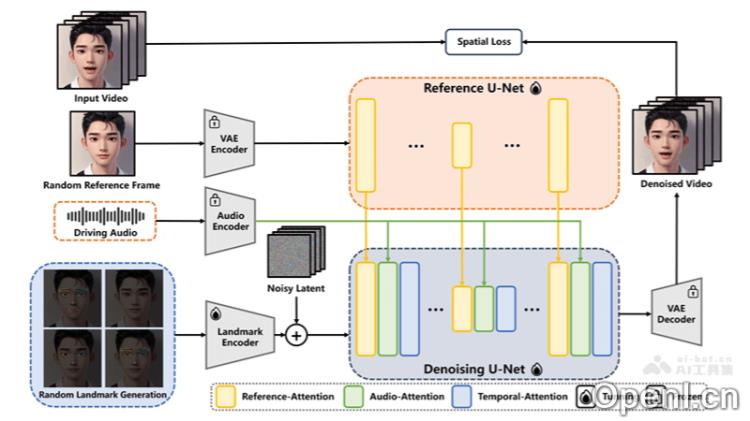
- 音频特征提取:EchoMimic对输入音频进行深入分析,利用先进技术提取语音的节奏、音调等特征。
- 面部标志点定位:通过高精度面部识别算法,精准定位面部关键区域,为后续动画生成提供基础。
- 面部动画生成:结合音频特征与面部标志点位置信息,运用深度学习模型生成与语音同步的面部表情和口型变化。
- 多模态学习:将音频和视觉信息深度融合,生成的动画在视觉和语义上均与音频内容高度一致。
- 深度学习模型应用:
- 卷积神经网络(CNN):用于从面部图像中提取特征。
- 循环神经网络(RNN):处理音频信号的时间动态特性。
- 生成对抗网络(GAN):生成高质量的面部动画,确保视觉效果的逼真性。
- 创新训练方法:EchoMimic采用创新训练策略,允许模型或结合使用音频和面部数据,提高动画的自然度。
- 预训练和实时处理:使用在大量数据上预训练的模型,EchoMimic可快速适应新音频输入并实时生成面部动画。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。