OpenELM是Apple最新发布的一系列高效开源语言模型,涵盖了不同参数规模的版本,包括OpenELM-270M、OpenELM-450M、OpenELM-1_1B和OpenELM-3B。该系列模型采用创新的层间缩放策略,实现了参数的非均匀分配,从而提升了模型的准确性与效率。OpenELM在多个自然语言处理任务中表现出色,并且其代码和预训练模型权重均已开放,旨在推动开放研究和社区的发展。
OpenELM是什么
OpenELM是Apple公司最新推出的高效开源语言模型系列,包含OpenELM-270M、OpenELM-450M、OpenELM-1_1B和OpenELM-3B等多个版本,提供预训练和指令微调两种选择。该模型运用层间缩放策略,在Transformer架构的每一层中实现参数的非均匀分配,以增强模型的准确度和效率。OpenELM在公共数据集上进行了预训练,并在多个自然语言处理任务中展现出卓越的性能。其代码、预训练模型权重及训练和评估流程均已开放,旨在促进开放研究与社区的进一步发展。

OpenELM的基本信息
- 参数规模:OpenELM系列共包含八个模型,其中四个为预训练版本,四个为指令微调版本,参数规模从2.7亿到30亿不等(270M、450M、1.1B和3B)。
- 技术架构:OpenELM基于Transformer架构,采用层间缩放策略,通过调整注意力头数和前馈网络的乘数,实现参数的非均匀分配。该模型使用分组查询注意力(Grouped Query Attention,GQA)替代传统的多头注意力(Multi-Head Attention,MHA),并选用SwiGLU激活函数代替传统的ReLU,同时采用RMSNorm作为归一化层。
- 预训练数据:OpenELM使用多个公共数据集进行预训练,包括RefinedWeb、去重的PILE、RedPajama的子集以及Dolma v1.6的子集,总计约1.8万亿个token。
- 开源许可:OpenELM的代码、预训练模型权重和训练指南均在开放源代码许可证下发布,Apple还提供了将模型转换为MLX库的代码,以支持在Apple设备上的推理和微调。
OpenELM的官网入口
- arXiv研究论文:https://arxiv.org/abs/2404.14619
- GitHub模型权重和训练配置:https://github.com/apple/corenet
- 指令微调版模型Hugging Face地址:https://huggingface.co/collections/apple/openelm-instruct-models-6619ad295d7ae9f868b759ca
- 预训练版模型Hugging Face地址:https://huggingface.co/collections/apple/openelm-pretrained-models-6619ac6ca12a10bd0d0df89e

OpenELM的技术架构
- Transformer架构:OpenELM采用仅解码器的Transformer模型架构,广泛应用于自然语言处理,特别适合序列数据的处理。
- 层间缩放(Layer-wise Scaling):通过层间缩放技术,OpenELM有效分配每一层的参数,早期层使用较小的注意力和前馈网络维度,而后期层则逐渐增大这些维度。
- 分组查询注意力(Grouped Query Attention,GQA):GQA是一种改进的注意力机制,取代了传统的多头注意力,旨在提升模型处理长距离依赖的能力。
- RMSNorm归一化:OpenELM采用RMSNorm作为归一化层,帮助稳定训练过程。
- SwiGLU激活函数:在前馈网络中,OpenELM使用SwiGLU激活函数,一种门控激活函数,有助于捕捉复杂模式。
- RoPE位置编码:OpenELM使用旋转位置编码(Rotary Positional Embedding,RoPE),有效处理序列中元素的顺序信息。
- Flash注意力:在计算缩放点积注意力时,OpenELM采用Flash注意力,提供快速且内存高效的注意力计算。
OpenELM的性能表现
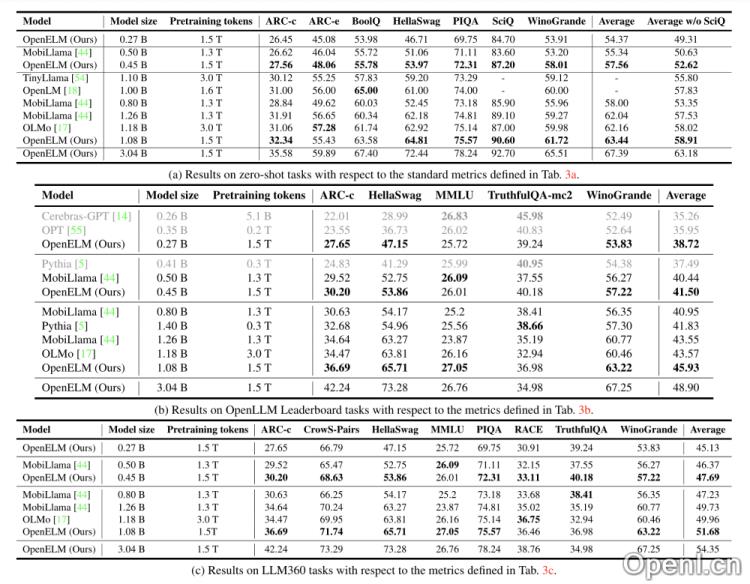
研究人员将OpenELM与PyThia、Cerebras-GPT、TinyLlama、OpenLM、MobiLlama和OLMo等模型进行了比较。在相似的模型规模下,OpenELM在ARC、BoolQ、HellaSwag、PIQA、SciQ和WinoGrande等主流任务测试中展现出更高的准确性。特别是,相较于OLMo模型,OpenELM在参数数量和预训练数据更少的情况下,依然保持较高的准确率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。