QA-MDT(Quality-aware Masked Diffusion Transformer)是由中国科学技术大学与科大讯飞共同开发的开源音乐生成模型。该模型能够基于文本描述创作出高质量且富有音乐性的作品,凭借创新的质量感知训练策略,QA-MDT在提升音乐波形质量的同时,展现出卓越的性能表现。它结合了掩蔽扩散变换器(MDT)和质量控制技术,为音乐制作及多媒体创作提供了强大的支持。
QA-MDT是什么
QA-MDT(Quality-aware Masked Diffusion Transformer)是中国科学技术大学与科大讯飞合作推出的开源音乐生成模型。该模型通过解析用户提供的文本描述,生成与之相符的高质量音乐,创新的质量感知训练方法帮助识别并提升音乐波形的质量。QA-MDT利用掩蔽扩散变换器(MDT)和质量控制技术,在大规模数据集上实现了卓越的性能,为音乐创作和多媒体制作提供了强有力的工具。
主要功能
- 文本生成音乐:用户可输入文本描述,QA-MDT将生成相应的音乐作品。
- 质量提升:该模型能够识别并优化生成音乐的质量,确保输出的歌曲具有高保真度。
- 数据集优化:通过对数据集的预处理及优化,提升音乐与文本之间的匹配程度。
- 多样化创作:模型能够生成多种风格的音乐,以满足不同用户的需求。
技术原理
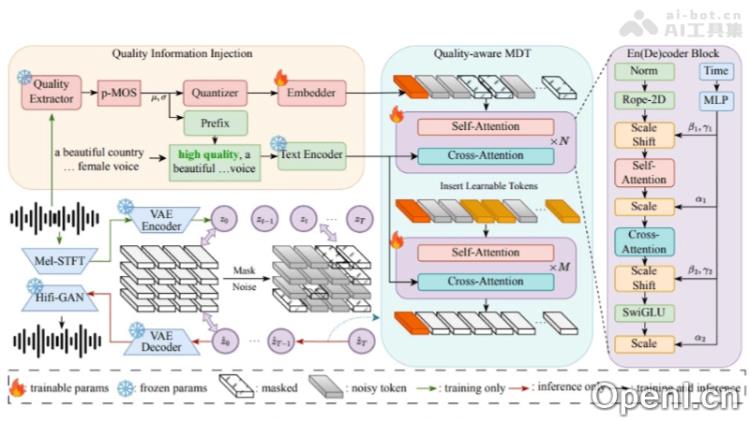
- 文本解析与音乐生成:利用自然语言处理技术解析用户文本,转化为音乐特征,并生成音乐。
- 质量感知训练机制:训练过程中采用质量评分模型(如伪MOS分数)来评估音乐样本的质量,确保生成音乐的高水平。
- 掩蔽扩散变换器(MDT):基于Transformer架构,通过掩蔽与预测音乐信号的部分内容,学习音乐的潜在表示,从而提高生成的准确性。
- 质量控制机制:在生成过程中,依据训练阶段获得的质量信息引导模型生成高品质音乐。
- 音乐与文本同步:利用大型语言模型(LLMs)和CLAP模型实现音乐信号与文本描述的同步,增强二者之间的一致性。
项目地址
- GitHub仓库:https://github.com/QA-MDT
- arXiv技术论文:https://arxiv.org/pdf/2405.15863v2
应用场景
- 广告与多媒体制作:为广告、影视、视频游戏及在线视频生成定制的背景音乐和音效。
- 音乐行业:为音乐制作人和作曲家提供创作灵感,辅助创作新音乐作品。
- 音乐教育:作为教学工具,帮助学生理解音乐理论与作曲技巧,或用于音乐练习和即兴演奏。
- 音频内容创作:为播客、有声书及其他音频内容创作原创音乐,提升听众体验。
- 智能助手与设备:为智能家居设备、虚拟助手等生成个性化音乐和声音,增强用户体验。
常见问题
- QA-MDT支持哪些格式的文本描述?:QA-MDT支持多种自然语言文本描述,用户可以用简单的句子表达他们的音乐需求。
- 生成的音乐可以用于商业用途吗?:由于QA-MDT是开源项目,生成的音乐作品通常可以使用,但请遵循相应的使用条款和许可证。具体情况请查阅项目文档。
- 如何获取QA-MDT的最新版本?:用户可以访问其GitHub仓库,获取最新版本及更新信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。