mPLUG-DocOwl 2是一款由阿里巴巴通义实验室mPLUG团队研发的多模态大型语言模型,专注于多页文档的理解与处理。它通过先进的高分辨率文档图像压缩技术,能够高效地解读文档图像,而无需依赖传统的光学字符识别(OCR)技术。mPLUG-DocOwl 2在多页文档理解的基准测试中取得了新的最高标准(SOTA),每页文档图像仅消耗324个token,从而显著降低显存占用和首包响应时间,提升了处理速度。该模型的训练分为三个阶段:单页预训练、多页预训练和多任务指令微调,支持对单页和多页文档中复杂问题的理解,包括跨页内容的关联和结构解析。
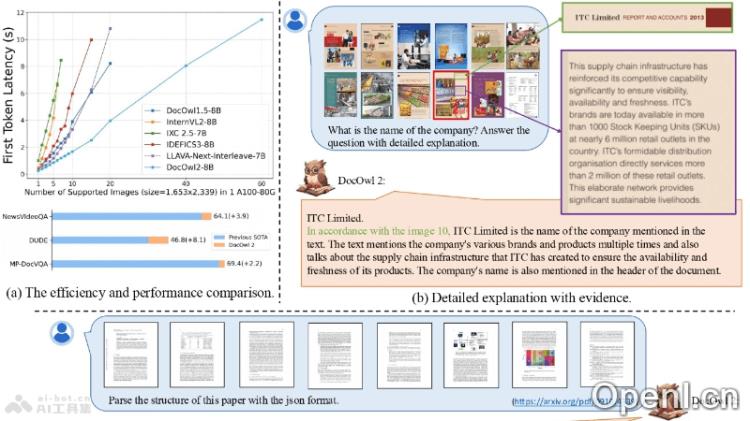
mPLUG-DocOwl2的主要功能
- 多页文档理解:无需OCR技术,直接从多页文档图像中提取和理解信息。
- 高分辨率图像处理:通过高分辨率文档图像压缩模块,将每页图像压缩至324个视觉token,减少显存占用并加快响应速度。
- 多页问答能力:能够解答与多页文档内容相关的问题,并提供详细解释及相关页码。
- 文档结构解析:解析文档的层级结构,并以JSON格式输出,便于后续数据处理与分析。
- 跨页内容关联:理解并关联多页文档中跨页的内容,从而实现更全面的结构理解。
- 高效处理:在单个A100-80G GPU上,能够同时处理多达60页的高清文档图片,显著提升处理效率。
mPLUG-DocOwl2的技术原理
- 高分辨率文档图像压缩(High-resolution DocCompressor):利用低分辨率全局视觉特征作为指导,通过cross-attention机制将高分辨率文档图像压缩为更少的视觉token。
- 形状自适应裁剪:根据文档的形状和尺寸进行自适应切割,以适应不同页面的布局需求。
- 视觉特征提取:通过视觉编码器(如ViT)提取切片的视觉特征,并通过H-Reducer模块进行特征合并和维度对齐。
- 跨注意力机制:在压缩过程中,使用全局图特征作为查询,切片特征作为键值对,通过cross-attention层实现特征的有效压缩。
- 全局与局部视觉特征结合:结合全局视觉特征(捕捉布局信息)和局部视觉特征(保留文本和图像细节),实现更精确的文档理解。
mPLUG-DocOwl2的项目地址
- GitHub仓库:https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl2
- arXiv技术论文:https://arxiv.org/pdf/2409.03420v2
mPLUG-DocOwl2的应用场景
- 法律文件分析:自动解析法律文件和案例,提取关键信息,支持法律研究与案件准备。
- 医疗记录管理:从医疗记录和报告中提取重要数据,支持病人护理、研究和行政管理。
- 学术研究:帮助研究人员快速理解和总结大量文献,加速科学发现与知识创新。
- 金融报告分析:自动化处理年度报告、财务报表及其他金融文档,提取关键财务指标与趋势。
- 文档处理:自动化处理发布的公告、法规和政策文件,提高服务效率。
常见问题
- mPLUG-DocOwl 2能否处理非英文文档?是的,mPLUG-DocOwl 2支持多种语言的文档理解。
- 该模型的训练数据来源是什么?模型训练使用了多种公共数据集和文档,以确保其通用性和准确性。
- 如何获取mPLUG-DocOwl 2的最新版本?用户可以访问其GitHub仓库获取最新的模型和更新信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。