AIGC动态欢迎阅读
原标题:视频大模型无损提速:删除多余token,训练时间减少30%,帧率越高效果越好 | NeurIPS
关键字:视频,图像,精度,时间,长度
文章来源:量子位
内容字数:0字
内容摘要:
克雷西 发自 凹非寺量子位 | 公众号 QbitAIDon’t look twice!
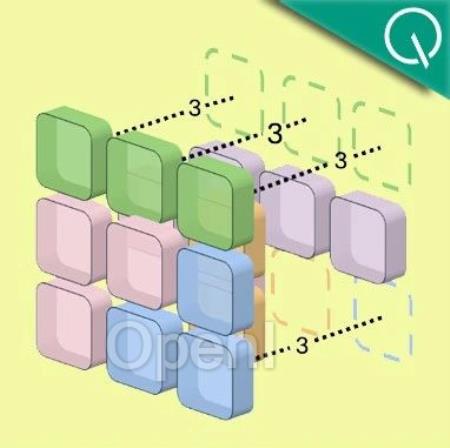
把连续相同的图像块合并成一个token,就能让Transformer的视频处理速度大幅提升。
卡内基梅隆大学提出了视频大模型加速方法Run-Length Tokenization(RLT),被NeurIPS 2024选为Spotlight论文。
在精度几乎没有损失的前提下,RLT可以让模型训练和推理速度双双提升。
一般情况下,利用RLT,Transformer视频识别模型的训练时间可缩短30%,推理阶段提速率提升更是可达67%。
对于高帧率和长视频,RLT的效果更加明显,30fps视频的训练速度可提升1倍,长视频训练token减少80%。
相比于传统的剪枝方法,RLT能用更小的精度损失实现更好的加速效果。
有人想到了电视剧中的评论,认为这项研究找到了在压缩空间中进行搜索的方法。
DeepMind科学家Sander Dieleman则评价称,这项研究是一种“非主流”(Off-the-grid)的创新方法,但比起其他复杂的非主流研究,又显得非常简洁。
重复图像块合为一个tokenRLT的核心原理,是利用
原文链接:视频大模型无损提速:删除多余token,训练时间减少30%,帧率越高效果越好 | NeurIPS
联系作者
文章来源:量子位
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。