sft 数据的诸多繁琐细节~
2024中国生成式AI大会(上海站)预告
2024年12月5日至6日,智猩猩联合主办的2024中国生成式AI大会将在上海举行。此次大会汇聚了来自各大机构的30多位专家嘉宾,包括北大(临港)大模型对齐中心执行主任徐骅、腾讯优图实验室天衍研究中心负责人吴贤等,欢迎各界人士积极报名参与。
数据清洗的重要性
在生成式AI的研发过程中,数据清洗是一个不可或缺的环节。尽管许多团队了解大语言模型(LLM)的基本方,但仍然面临清洗SFT(监督微调)数据的复杂性。随着时间的推移,去年的数据可能不再适用,因此定期更新和清洗数据显得尤为重要。
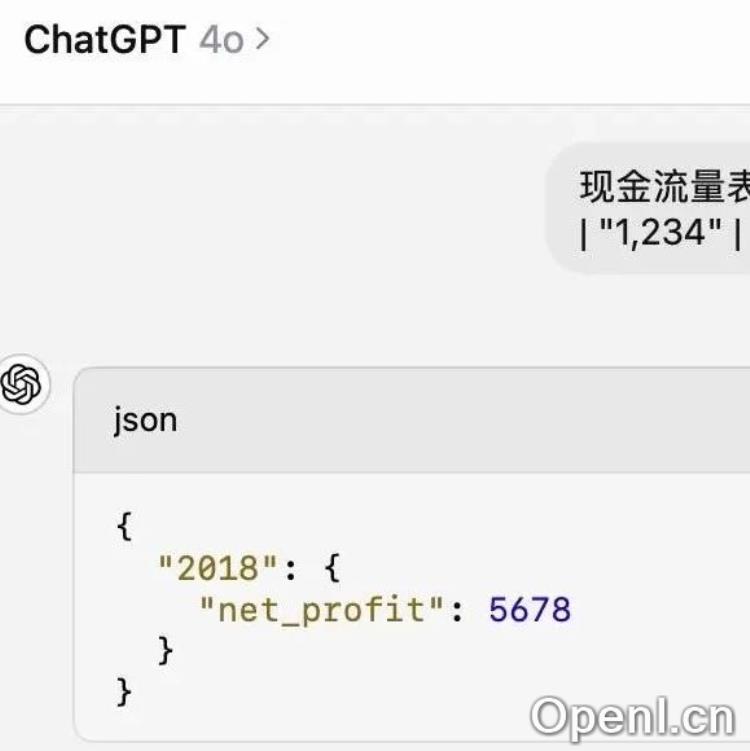
JSON格式输出的复杂性
文章中以“以JSON格式输出”为例,探讨了数据清洗的细节。虽然JSON格式看似简单,但实际操作中却存在多种变体和规则,比如indent值的选择、是否带有markdown格式等。对于模型的训练,统一格式至关重要,以避免输出不一致的问题。
数值任务中的格式问题
在处理数值任务时,使用float/int类型还是str类型的问题也引发了讨论。数值的单位常常被忽视,而这会直接影响模型的输出准确性。为了解决这一问题,可以在SFT数据中增加单位字段,以确保信息的完整性。
总结
总的来说,生成式AI的训练过程中,数据清洗和格式统一是基础而重要的环节。虽然这些工作看似繁琐,但只有通过不断的实践,才能真正掌握其中的复杂性。期待在2024中国生成式AI大会上,行业专家们分享更多前沿技术与经验。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下矩阵账号之一,聚焦大模型开启的通用人工智能浪潮。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。