BlueLM-V-3B是一款由vivo AI Lab与香港中文大学MMLab联合研发的多模态大型语言模型(MLLM),旨在高效地将其部署于移动设备。该模型具备小巧的体积(2.7B语言参数和400M视觉参数)、迅捷的生成速度(24.4 token/s)以及卓越的性能(在OpenCompass基准测试中获得66.1分),通过优化动态分辨率和硬件感知部署,显著提升了在手机上的推理效率和性能。
BlueLM-V-3B是什么
BlueLM-V-3B是由vivo AI Lab与香港中文大学MMLab共同开发的一种新型算法和系统协同设计方法,旨在将多模态大型语言模型(MLLM)高效地应用于移动设备。该模型以其小尺寸(2.7B语言参数及400M视觉参数)、快速的生成能力(24.4 token/s)和强大的性能(OpenCompass基准测试得分66.1)而闻名,采用优化的动态分辨率策略和针对硬件的智能部署,极大地提升了手机端的推理效率和性能。
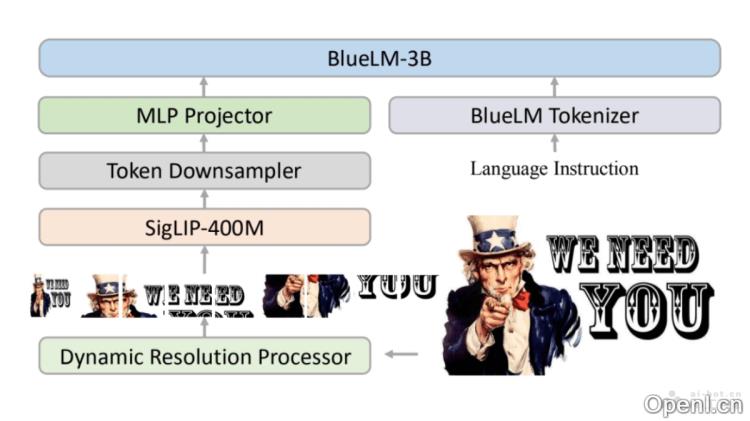
BlueLM-V-3B的主要功能
- 多模态理解:能够处理和整合文本、图像等多种数据形式,提供更为丰富的交互体验及深刻的上下文理解。
- 实时处理:在移动设备上实现快速响应,适合需要即时反馈的场景,如增强现实和实时翻译。
- 隐私保护:支持本地处理,减少数据传输,从而增强用户隐私。
- 高效部署:经过优化的模型设计使其能够适应移动设备的计算和内存限制,确保在资源有限的硬件上也能高效运行。
- 高性能:在相对较小的参数量下,性能与更大参数量的模型不相上下。
- 跨语言能力:支持多种语言的理解,使模型在不同语言环境中均具备良好适应性。
BlueLM-V-3B的技术原理
- 算法设计:
- 动态分辨率处理:重新设计动态图像分辨率策略,以适应高分辨率图像的理解需求,减少图像令牌数量,从而简化部署过程。
- 宽高比优化:引入参数α,选择更合适的宽高比,降低图像放大效果,优化训练与部署效率。
- 系统设计:
- 批量图像编码:利用NPU的并行处理能力,加速图像补丁的批量处理,提高图像编码速度。
- 流水线并行处理:在图像编码过程中设计流水线并行处理机制,以隐藏Conv2D操作的执行延迟。
- 令牌下采样器:通过信息合并与融合,减少图像令牌数量,从而适应NPU的处理能力。
- 分块计算:针对长输入令牌采用分块策略,以平衡并行处理与NPU性能。
- 模型量化:采用INT8和INT4精度对模型权重进行量化,同时保持LLM激活的INT16和ViT激活的FP16精度,以平衡计算效率与模型准确性。
- 整体框架:在模型初始化时同时加载ViT和LLM模型,用户上传图像后可立即开始处理,同时接收指令,从而提高响应速度和内存使用效率。
BlueLM-V-3B的项目地址
- arXiv技术论文:https://arxiv.org/pdf/2411.10640
BlueLM-V-3B的应用场景
- 增强现实(AR):在移动设备上提供实时增强现实体验,例如利用手机摄像头识别现实世界中的物体,并提供相关信息。
- 实时翻译:在跨语言交流中,实现语音或图像中文字的即时翻译,帮助用户克服语言障碍。
- 教育辅助:作为学习工具,帮助学生理解复杂概念,提供互动式的图像与文本学习体验。
- 视觉问答(VQA):用户可以基于拍照或上传的图片询问相关问题,模型会提供准确的答案。
- 图像与文档理解:在办公自动化中,能够理解和处理图像及文档内容,如自动识别发票、合同等文档信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。