基于视觉的移动设备任务自动化框架VisionTasker
原标题:西安交大最新成果!端侧智能体VisionTasker:让AI自动完成手机中各种任务
文章来源:智猩猩GenAI
内容字数:7983字
2024中国生成式AI大会(上海站)预告
2024中国生成式AI大会将于12月5-6日在上海举办,由智猩猩共同主办。此次大会将吸引30多位知名嘉宾参与演讲,包括北大(临港)大模型对齐中心的徐骅教授、腾讯优图实验室的吴贤研究员等。大会涵盖了大模型峰会、AI基础设施峰会以及多场技术研讨会,是AI领域的重要盛会。
引言
随着人工智能技术的快速发展,移动任务自动化逐渐成为研究热点。西安交通大学智能网络与网络安全教育部重点实验室(MOE KLINNS Lab)提出的VisionTasker框架,结合视觉UI理解和大语言模型(LLM)任务规划,旨在提升移动设备上的任务自动化能力。该研究已被国际顶会UIST 2024收录。
VisionTasker框架介绍
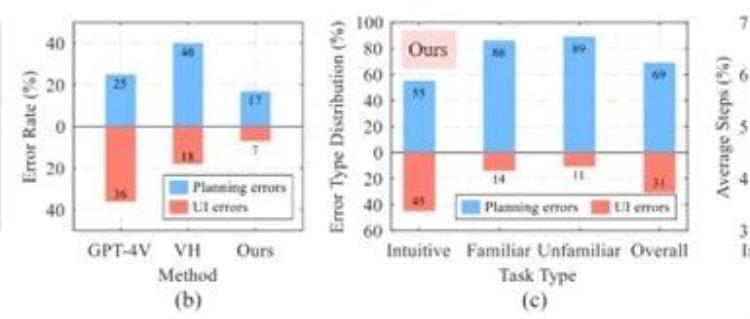
VisionTasker是一个两阶段开源框架,首先通过视觉UI理解将界面转换为自然语言,消除了对视图层次结构的依赖;其次,利用LLM进行逐步任务规划,提高执行准确性。其在多个公开数据集上的表现超越了传统方法,尤其在处理人类不熟悉的任务时显示出优越性。
实验与结果
研究团队进行了广泛的实验,比较了VisionTasker与其他UI理解方法的性能。结果表明,VisionTasker在多项指标上均表现出显著优势,特别是在跨语言应用及复杂任务自动化方面。通过与人类评估者的比较,VisionTasker在147个真实世界任务中展现了与人类相当的完成率,甚至在某些任务中超越了人类表现。
结论
VisionTasker克服了现阶段移动任务自动化对视图层级结构的依赖,展示了其在用户界面表示及任务执行方面的创新性和实用性。通过集成演示编程(PBD)机制,VisionTasker在任务自动化领域展现出广阔的前景,为未来的智能自动化执行任务提供了新的思路。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下矩阵账号之一,聚焦大模型开启的通用人工智能浪潮。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。