OmniBooth是华为诺亚方舟实验室与香港科技大学研究团队联手打造的图像生成框架。该框架支持通过文本提示或图像参考进行空间控制与实例级定制,用户可以通过自定义的掩码以及相关的文本或图像,实现对图像中对象位置与属性的精确掌控,从而提升文本到图像合成技术的可控性与实用性。
OmniBooth是什么
OmniBooth是一个创新的图像生成框架,旨在通过文本提示或图像参考实现空间控制与实例定制。该框架利用用户定义的掩码,以及与之相关的文本或图像,精准地操控图像中对象的位置和特征,从而提升图像合成的灵活性和实用性。OmniBooth的核心在于高维潜在控制信号的创新应用,能够无缝融合空间信息、文本与图像条件,实现细致入微的图像合成控制。
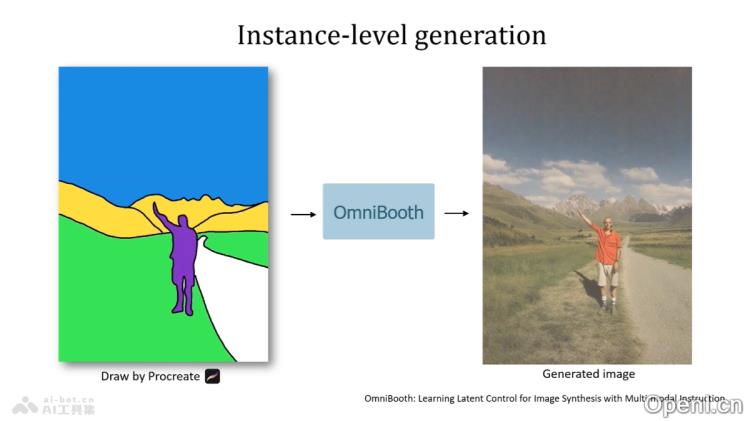
OmniBooth的主要功能
- 多模态指令控制:支持通过文本提示或图像参考来指导图像生成,实现在不同模态下的图像合成。
- 空间控制与实例级定制:用户可以自定义掩码,并通过文本或图像来精准控制图像中对象的定位和属性,实现个性化定制。
- 高维潜在控制信号:该框架利用潜在控制信号的技术,整合空间、文本和图像条件,提供统一的表示方式。
- 灵活性和实用性:用户可根据需求选择文本或图像作为多模态输入,显著增强生成图像的灵活性与实用性。
OmniBooth的技术原理
- 多模态嵌入提取:
- 文本嵌入:使用CLIP文本编码器提取文本提示的嵌入向量。
- 图像嵌入:应用DINOv2特征提取器获取图像参考的嵌入向量,确保图像的身份和空间特征得以保留。
- 潜在控制信号:文本与图像的嵌入向量被绘制到高维潜在控制信号中,这些信号包含丰富的空间信息和潜在特征。
- 空间变形技术:通过空间变形技术,将图像嵌入有效转换并整合到潜在控制信号中,保持图像的细节与结构。
- 特征对齐网络与边缘损失函数:
- 开发特征对齐网络,将条件信息注入潜在特征中。
- 提出边缘损失,以增强高频区域的监督,从而提升生成图像的质量与结构对齐。
- 多尺度训练与随机模态选择策略:在训练阶段,该模型采用多尺度训练和随机模态选择策略,以提升对不同分辨率和模态输入的适应能力。
OmniBooth的项目地址
- 项目官网:len-li.github.io/omnibooth
- GitHub仓库:https://github.com/EnVision-Research/OmniBooth
- HuggingFace模型库:https://huggingface.co/lilelife/OmniBooth
- arXiv技术论文:https://arxiv.org/pdf/2410.04932
OmniBooth的应用场景
- 数据集生成:为机器学习模型生成所需的合成数据集,尤其在现实世界数据难以获得的情况下。
- 内容创作:艺术家和设计师可以通过文本或图像指导,创作新的图像内容,如插画、概念艺术等。
- 游戏与娱乐:在游戏开发中,快速生成游戏环境、角色和道具的原型设计。
- 虚拟现实(VR)与增强现实(AR):为虚拟环境创建逼真的背景和对象,以提升用户体验。
- 广告与营销:根据客户需求快速生成广告图像和营销材料。
常见问题
- OmniBooth支持哪些输入格式?:OmniBooth支持文本提示和图像参考作为输入,用户可以根据需要灵活选择。
- 如何自定义图像生成?:用户可以定义掩码并提供相应的文本或图像,精确控制图像中对象的位置和属性。
- OmniBooth适用于哪些行业?:它可广泛应用于数据生成、艺术创作、游戏开发、虚拟现实等多个行业。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。