OpenScholar是一款由华盛顿大学与艾伦AI研究所联合开发的检索增强型语言模型,旨在帮助科研人员通过检索和整合科学文献中的相关资料来解答问题。借助于庞大的科学论文数据库、定制化的检索器和重排器以及优化的8B参数语言模型,OpenScholar能够生成基于真实文献的准确回答。与现有的专有和开源模型相比,OpenScholar在提供事实性回答和准确引用方面表现更为出色。在ScholarQABench的评测中,OpenScholar-8B的正确性比GPT-4o高出5%,比PaperQA2高出7%。此外,所有相关代码和数据均已开源,有助于推动和加速科学研究。
OpenScholar是什么
OpenScholar是一个先进的文献检索与回答系统,旨在为科学研究提供支持。它利用大规模的科学文献数据库,结合专用的检索工具和优化的语言模型,为用户提供基于文献的可靠答案。通过这种方式,OpenScholar不仅提升了信息获取的效率,还确保了回答的准确性和引用的可靠性。
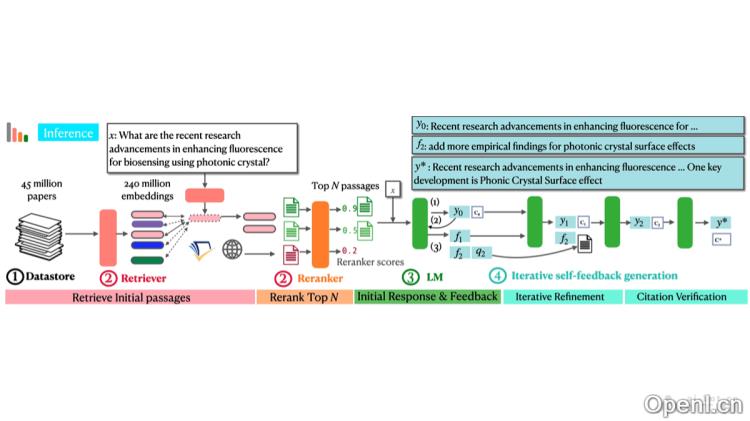
OpenScholar的主要功能
- 文献检索与整合:高效检索大量科学文献,并综合相关信息以回答用户的查询。
- 基于引用的反馈回答:生成的回答包含准确引用,增强了信息的可靠性和透明度。
- 跨学科应用:在计算机科学、生物医学、物理学、神经科学等多个领域均可适用。
- 提升检索效率:通过专门设计的检索器和重排器,显著提高相关文献的检索效率和准确性。
- 自我反馈与迭代:运用自我反馈机制不断迭代改进回答,提升回答质量和引用的完整性。
OpenScholar的技术原理
- 数据存储(OpenScholar Datastore):包含超过4500万篇科学论文及其2.37亿段落嵌入,为检索提供了坚实的数据基础。
- 专业化的检索器与重排器:特别为科学文献数据存储训练的检索工具,能够有效识别和排序相关文献段落。
- 优化的8B参数语言模型:针对科学文献合成任务进行优化的8B参数大型语言模型,在性能和计算效率之间取得良好平衡。
- 自我反馈生成机制:在推理过程中,基于自然语言的反馈不断迭代细化模型输出,可能需要额外的文献检索,以改善回答质量并填补引用空白。
- 迭代检索增强:在生成初步回答后,模型会提供反馈,指导后续检索,以迭代方式不断改进答案,直到所有反馈问题得到解决。
OpenScholar的项目地址
- 项目官网:allenai.org/blog/openscholar
- GitHub仓库:https://github.com/AkariAsai/OpenScholar
- HuggingFace模型库:https://huggingface.co/collections/OpenScholar/openscholar-v1-67376a89f6a80f448da411a6
- arXiv技术论文:https://arxiv.org/pdf/2411.14199
OpenScholar的应用场景
- 科研辅助:帮助研究人员快速获取最新研究成果,保持领域内的前沿认知。
- 文献综述:在撰写学术论文或报告时,作者能有效整合和总结大量文献,提高写作效率。
- 跨学科研究:因其覆盖多个科学领域,OpenScholar助力研究人员探索不同学科间的联系与交叉。
- 教育与学习:为学生和教师提供深入的文献分析和总结,辅助学习与教学。
- 技术监控:企业研发部门可利用其监控科技发展趋势,特别是在快速变化的技术领域。
常见问题
- OpenScholar如何提高回答的准确性?:通过结合大规模文献数据库与优化的检索工具,OpenScholar能提供基于文献的准确回答。
- 是否支持多种科学领域的研究?:是的,OpenScholar适用于计算机科学、生物医学、物理学等多个领域。
- 用户如何访问OpenScholar的资源?:用户可以通过项目官网和GitHub仓库访问相关资源与文档。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。