SmolVLM是Hugging Face推出的一款轻量级视觉语言模型,旨在为设备端推理提供高效解决方案。它以20亿的参数量,优化了内存占用并提升了处理速度。SmolVLM有三个版本可供选择:SmolVLM-Base,适合下游任务的微调;SmolVLM-Synthetic,基于合成数据进行微调;以及SmolVLM-Instruct,专为交互式应用而设计的指令微调版本。
SmolVLM是什么
SmolVLM是一款由Hugging Face开发的轻量级视觉语言模型,专注于设备端推理。其设计以20亿参数为基础,实现了卓越的内存使用效率和处理速度。SmolVLM有三个版本,旨在满足不同用户的需求:SmolVLM-Base适合于下游任务的微调;SmolVLM-Synthetic则基于合成数据进行微调;而SmolVLM-Instruct则是指令微调版本,适合直接用于交互式应用。该模型借鉴了Idefics3的理念,采用SmolLM2 1.7B作为语言主干,并通过像素混洗技术提高了视觉信息的压缩效率。经过在Cauldron和Docmatix数据集的训练,优化了图像编码及文本处理能力。
SmolVLM的主要功能
- 设备端推理:SmolVLM专为设备端推理设计,能够在笔记本电脑、消费级GPU或移动设备等资源有限的环境中高效运作。
- 微调能力:模型提供三个版本以满足不同需求:
- SmolVLM-Base用于下游任务的微调;
- SmolVLM-Synthetic基于合成数据进行微调;
- SmolVLM-Instruct指令微调版本,适合直接应用于交互式场景。
- 优化的架构设计:该模型借鉴了Idefics3理念,使用SmolLM2 1.7B作为语言主干,并通过像素混洗策略提高视觉信息的压缩率,从而实现更高效的视觉信息处理。
- 处理长文本和多张图像:训练数据集包括Cauldron和Docmatix,对SmolLM2进行了上下文扩展,使其能够处理更长的文本序列和多张图像。
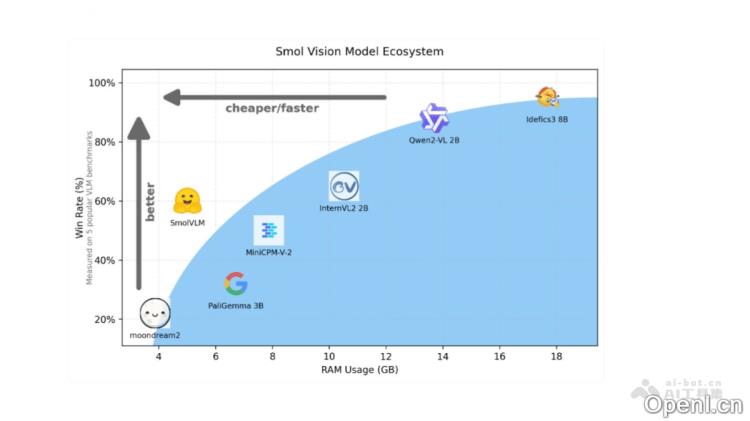
- 低内存占用:SmolVLM将384×384像素的图像块编码为81个tokens,而Qwen2-VL则需要1.6万个tokens,显著降低了内存占用。
- 高吞吐量:在多个基准测试中,SmolVLM的预填充吞吐量比Qwen2-VL快3.3到4.5倍,生成吞吐量快7.5到16倍。
- 开源模型:SmolVLM完全开源,所有模型检查点、VLM数据集、训练配方和工具均在Apache 2.0许可证下发布。
- 训练数据集:SmolVLM涵盖了Cauldron和Docmatix,并对SmolLM2进行了上下文扩展,使其能够处理更长的文本序列和多张图像。
SmolVLM的项目地址
- Github仓库:https://github.com/huggingface/blog/blob/main/smolvlm.md
- HuggingFace模型库:https://huggingface.co/blog/smolvlm
- 在线体验Demo:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
- 数据集完整列表:https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct/blob/main/smolvlm-data.pdf
SmolVLM的应用场景
- 视频分析:SmolVLM展现出了在基本视频分析任务中的潜力,尤其是在计算资源受限的情况下。在CinePile基准测试中,其得分达到27.14%,显示了在视频理解能力上的竞争力。
- 视觉语言处理:SmolVLM为开发者和研究人员提供了强大的工具,便于进行视觉语言处理,无需投入高昂的硬件费用。
- 本地部署:该小型模型支持在浏览器或边缘设备上进行本地部署,降低推理成本,并支持用户自定义。
- AI普及化:SmolVLM的发展有望拓展视觉语言模型的应用范围,使复杂的AI系统更加普及和易于访问,为更广泛的受众提供强大的机器学习能力。
常见问题
- SmolVLM是否适合移动设备使用?是的,SmolVLM专为设备端推理而设计,特别适合在移动设备和资源有限的环境中使用。
- 我如何微调SmolVLM?您可以选择不同的版本,如SmolVLM-Base、SmolVLM-Synthetic或SmolVLM-Instruct,根据您的具体需求进行微调。
- SmolVLM是开源的吗?是的,SmolVLM完全开源,您可以访问所有模型检查点和工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。