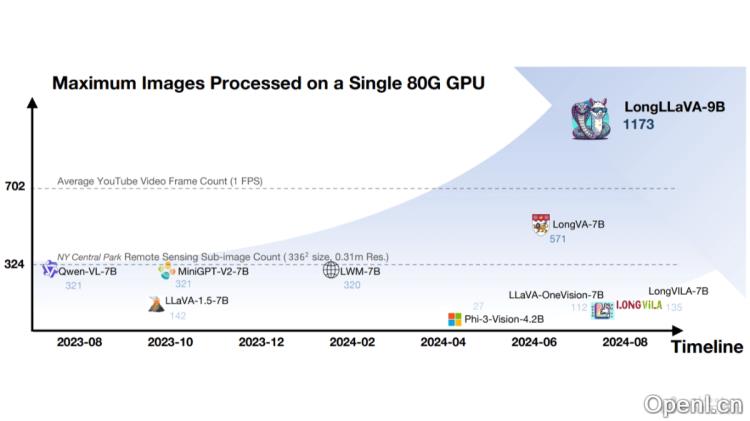
LongLLaVA是一款先进的多模态大型语言模型(MLLM),由香港中文大学(深圳)的研究团队研发。该模型基于一种混合架构,巧妙地结合了Mamba和Transformer模块,能够高效地处理大量图像,尤其在视频理解和高分辨率图像分析方面表现突出。LongLLaVA在单个A100 80GB GPU上能同时处理近千张图像,展现出卓越的性能和低内存消耗的优势,尤其在多模态长上下文理解任务中表现卓越。
LongLLaVA是什么
LongLLaVA是一款多模态大型语言模型(MLLM),由香港中文大学(深圳)的研究者们推出。该模型采用混合架构,结合Mamba和Transformer模块,显著提高了处理海量图像数据的效率。LongLLaVA能够在单个A100 80GB GPU上一次性处理多达1000张图像,同时保持高效能和低内存消耗。该模型利用2D池化技术压缩图像token,显著降低计算成本,同时保留重要的空间关系信息。LongLLaVA在视频理解、高分辨率图像分析及多模态代理等场景中展现出卓越的表现,尤其在检索、计数和排序等任务中表现出色。
主要功能
- 多模态长上下文理解:能够处理包含大量图像的长上下文信息,适合视频理解和高分辨率图像分析等应用。
- 高效图像处理:在单个GPU上高效处理多达1000张图像,展示了在处理大规模视觉数据时的卓越能力。
- 混合架构优化:结合Mamba与Transformer架构,平衡了模型的效率与效果。
- 数据构建与训练策略:采用独特的数据构建方法和分阶段的训练策略,增强模型对多图像场景的理解能力。
- 优异的基准测试表现:在多个基准测试中展现出色的性能,尤其在检索、计数和排序任务中表现突出。
技术原理
- 混合架构:基于混合架构,整合了Mamba和Transformer模块,Mamba模块具备线性时间复杂度的序列建模能力,而Transformer模块则处理复杂的上下文学习任务。
- 2D池化压缩:运用2D池化技术压缩图像token,减少了token数量,同时保持了图像间的空间关系。
- 数据构建:在数据构建过程中考虑图像之间的时间和空间依赖性,设计独特的数据格式,帮助模型更好地理解多图像场景。
- 渐进式训练策略:模型采用三阶段训练方法,包括单图像对齐、单图像指令调优和多图像指令调优,逐步提升模型处理多模态长上下文的能力。
- 效率与性能平衡:在确保高性能的同时,通过架构与训练策略的优化,实现低内存消耗与高吞吐量,展现出在资源管理上的优势。
- 多模态输入处理:能够处理多种输入形式,包括图像、视频和文本,能够在内部混合架构中有效统一管理预处理输入。
项目地址
应用场景
- 视频理解:能够处理长视频序列,适用于视频内容分析、检测、视频摘要和视频检索等任务。
- 高分辨率图像分析:在处理高分辨率图像的场景中,如卫星图像分析、医学影像诊断以及病理切片分析,能够分解图像为子图像并理解空间依赖性。
- 多模态助理:作为多模态助理,提供基于图像和文本的实时信息检索和个性化服务。
- 远程监测:在遥感领域,处理大量遥感图像,用于环境监测、城市规划和农业分析。
- 医疗诊断:辅助医生进行病理图像分析,提高诊断的准确性和效率。
常见问题
- LongLLaVA的处理能力如何? LongLLaVA能够在单个A100 80GB GPU上同时处理近千张图像,效率极高。
- LongLLaVA适合哪些应用场景? 该模型适用于视频理解、高分辨率图像分析、医疗诊断等多个领域。
- 如何获取LongLLaVA的技术文档? 您可以访问其GitHub仓库或查阅相关的arXiv技术论文以获取详细信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。