逐步介绍MoE核心组件。
原标题:50张图,直观理解混合专家(MoE)大模型
文章来源:智猩猩GenAI
内容字数:10576字
2024中国生成式AI大会预告
12月5-6日,智猩猩联合主办的2024中国生成式AI大会(上海站)将举行。主会场将进行大模型峰会和AI Infra峰会,同时分会场将讨论端侧生成式AI、AI视频生成和具身智能等技术。欢迎大家报名参与!
1. 混合专家(MoE)简介
混合专家(MoE)是一种通过多个子模型(专家)来提升大型语言模型(LLM)质量的技术。MoE的主要组成部分包括“专家”和“路由网络”。专家是前馈神经网络(FFNN),而路由网络则负责选择特定输入的专家。这种架构允许模型在处理特定任务时激活最相关的专家,从而提高效率。
2. 专家的作用
专家在MoE中起到分工的作用,每个专家在训练过程中学习特定的信息。尽管解码器模型中的专家不一定专注于特定领域,但它们在处理特定类型的词元时表现出一致性。通过这样的分工,MoE能够在推理时使用最合适的专家,从而提高模型的整体性能。
3. 路由机制
路由网络是MoE中至关重要的组件,它决定了在推理和训练过程中选择哪些专家。该网络通过计算输入的路由权重,生成概率分布,以选择最匹配的专家。负载均衡是路由过程中需要关注的关键问题,确保所有专家在训练和推理过程中得到均衡的使用。
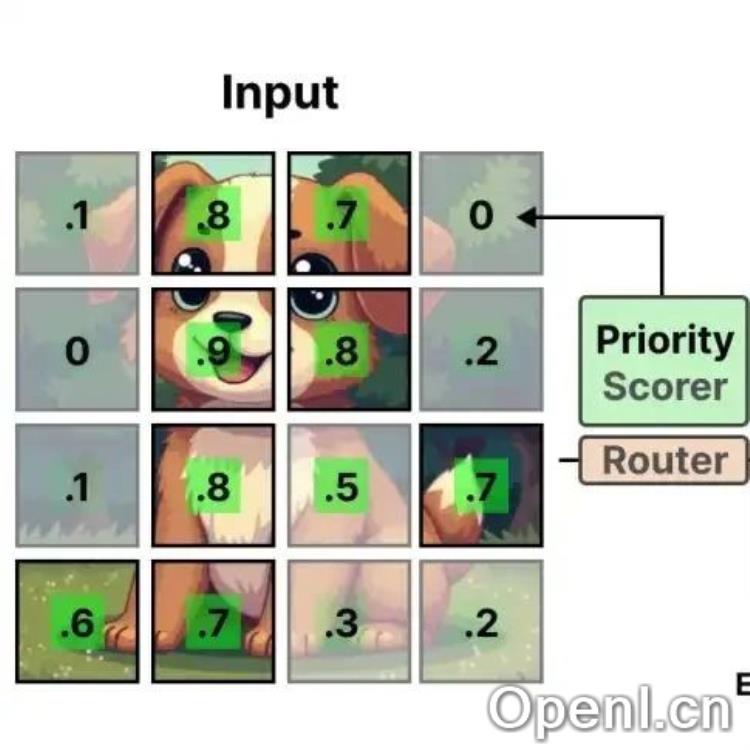
4. 视觉模型中的MoE
MoE技术不仅适用于语言模型,也在视觉模型中展现出潜力。视觉混合专家(V-MoE)通过将传统的前馈神经网络替换为稀疏MoE,能够提升图像模型的处理能力。此技术通过优先处理重要的小块,从而提高模型的效率和准确性。
5. 总结与展望
混合专家技术为大型语言和视觉模型提供了新的发展方向,随着技术的不断进步,MoE将在多个模型系列中得到广泛应用。未来,MoE将继续发挥其在计算效率和模型性能上的优势,推动AI领域的发展。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。