Delta-CoMe是一种创新的增量压缩算法,由清华大学NLP实验室与OpenBMB开源社区、北京大学和上海财经大合研发。该算法使得在一台80G的A100 GPU上可以轻松加载多达50个7B模型,显著节省约8倍的显存,同时在压缩后的模型性能几乎与未压缩的微调模型相当。Delta-CoMe结合了低秩分解与低比特量化技术,利用模型参数增量(Delta)的低秩特性,实现了高效的混合精度压缩。
Delta-CoMe是什么
Delta-CoMe是一种前沿的增量压缩算法,旨在优化大型语言模型(LLMs)的存储和推理效率。通过创新的压缩技术,Delta-CoMe在保证模型性能的同时,显著降低了对硬件资源的需求,特别适用于处理复杂任务如数学计算、代码生成和多模态应用。
Delta-CoMe的主要功能
- 高效模型压缩:通过混合精度压缩技术,大幅降低大型语言模型的存储和内存需求,使得在有限的硬件环境中可以部署更多模型。
- 精准性能保持:在压缩过程中,确保模型在复杂任务中的性能几乎不受影响,特别是在解决数学问题、生成代码和多模态任务时表现优异。
- 灵活的多任务处理:支持同时部署多个功能不同的模型,适合多租户环境和多任务处理,提高了模型应用的灵活性和效率。
- 显著提升推理速度:采用Triton kernel算子,推理速度较传统PyTorch实现提升近3倍,进一步优化了模型的运行效率。
Delta-CoMe的技术原理
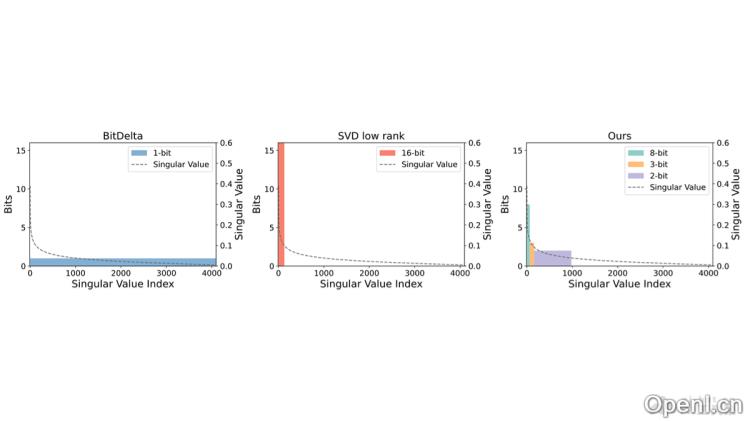
- 低秩分解技术:通过奇异值分解(SVD)对模型参数增量(Delta)进行低秩分解,发现大部分变化集中在少数主要成分上。
- 混合精度量化:依据低秩分解的结果,为不同的奇异向量分配适当的位宽。较大奇异值对应的奇异向量使用更高精度表示,而较小的奇异值则使用较低精度,从而减少存储需求。
- 长尾分布的有效利用:Delta-CoMe发现Delta参数的奇异值呈现长尾特征,主要集中在较小的数值上。因此,对小奇异值的奇异向量进行更激进的压缩,对大奇异值的奇异向量则保留更高的精度。
- 兼容性与泛化能力:该方法不仅适用于特定模型或任务,还具有良好的泛化能力,可以与多种主干模型(如Llama-2、Llama-3和Mistral)兼容,并在多种任务上保持优异性能。
- 硬件优化支持:为进一步提升推理速度,Delta-CoMe实现了针对混合精度量化的Triton kernel算子,确保在硬件上的有效部署。
Delta-CoMe的项目地址
- GitHub仓库:https://github.com/thunlp/Delta-CoMe
- arXiv技术论文:https://arxiv.org/pdf/2406.08903
Delta-CoMe的应用场景
- 多租户服务:在云计算环境中,支持在有限硬件资源上为每位用户提供专属模型,有效节省显存和计算资源。
- 多任务处理:在需要同时处理多种不同任务的环境中,能够有效压缩并部署多种任务模型。
- 边缘设备部署:在资源受限的边缘计算设备上,降低模型的存储与内存占用。
- 模型微调服务:对于需要频繁调整以适应新数据或任务的模型,使用压缩后的增量微调,减少存储和推理成本。
- 学术研究与开发:为研究人员和开发者提供压缩与部署大型语言模型的能力,助力实验与开发,不受硬件条件的限制。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。