ConsisID是一种由北京大学与鹏城实验室等机构联合开发的文本到视频(Text-to-Video,IPT2V)生成模型。它利用频率分解技术确保视频中人物身份的一致性。该模型采用免调优(tuning-free)Diffusion Transformer(DiT)架构,结合低频全局特征与高频细节特征,运用分层训练策略生成高质量、可编辑且身份一致性强的视频。ConsisID在多个评估维度上超越了现有技术,推动了身份一致性视频生成技术的进步。
ConsisID是什么
ConsisID是一个先进的文本到视频生成模型,旨在通过频率分解技术保持视频中人物的身份一致性。该模型采用免调优的Diffusion Transformer架构,结合低频全局特征与高频细节特征,通过分层训练策略,能够生成高质量且易于编辑的视频内容。ConsisID在多个评估标准上表现出色,推进了身份一致性视频生成的技术发展。
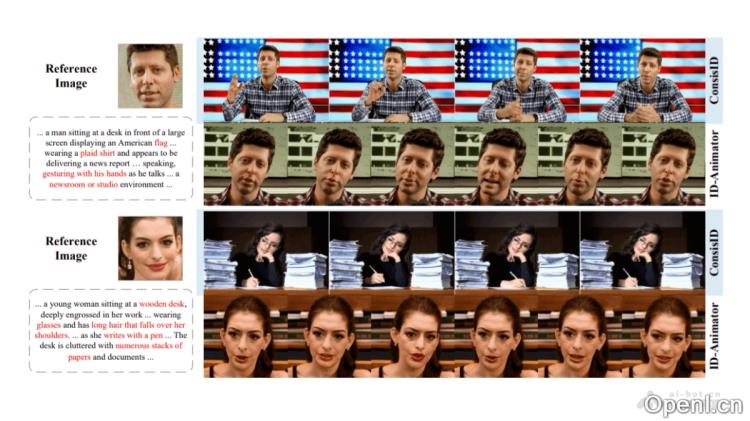
ConsisID的主要功能
- 身份保持:在生成视频时,确保人物身份的一致性,使视频中的人物特征与提供的参考图像相符合。
- 高质量视频生成:生成视觉上真实、细节丰富的视频内容。
- 无须微调:作为免调优模型,用户无需针对每个新案例进行微调,使用更加简便。
- 可编辑性:用户可以通过文本提示控制视频内容,包括人物的动作、表情以及背景等元素。
- 泛化能力:能够处理训练数据之外的人物,提升模型的适应性。
ConsisID的技术原理
- 频率分解:
- 低频控制:利用全局人脸特征提取器,将参考图像和人脸关键点编码成低频特征,融入网络的浅层结构,降低训练难度。
- 高频控制:设计局部人脸特征提取器,捕捉高频细节并注入Transformer模块,以增强模型对细微特征的保留能力。
- 层次化训练策略:
- 粗到细训练:模型先学习全局信息,再逐步细化到局部信息,确保视频在空间和时间上的一致性。
- 动态掩码损失(Dynamic Mask Loss):通过人脸mask约束损失函数,使模型专注于人脸区域的生成。
- 动态跨脸损失(Dynamic Cross-Face Loss):引入跨面部的参考图像,提升模型对未见身份的泛化能力。
- 特征融合:通过人脸识别骨干网络和CLIP图像编码器提取特征,并基于Q-Former融合特征,生成包含高频语义信息的内在身份特征。
- 交叉注意力机制:利用交叉注意力机制,使模型能够与预训练模型生成的视觉标记进行有效互动,增强DiT中的高频信息。
ConsisID的项目地址
- 项目官网:pku-yuangroup.github.io/ConsisID
- GitHub仓库:https://github.com/PKU-YuanGroup/ConsisID
- HuggingFace模型库:https://huggingface.co/datasets/BestWishYsh/ConsisID
- arXiv技术论文:https://arxiv.org/pdf/2411.17440
- 在线体验Demo:https://huggingface.co/spaces/BestWishYsh/ConsisID
ConsisID的应用场景
- 个性化娱乐:用户可以创建与自己或指定人物相似的虚拟形象,用于社交媒体或个人娱乐。
- 虚拟主播:在新闻播报或网络直播中,利用ConsisID生成的虚拟主播进行24小时不间断的工作。
- 电影和电视制作:在电影后期制作中,用于生成特效场景中的角色,或创建全新的虚拟角色。
- 游戏行业:为游戏角色设计提供原型,或在游戏中生成与玩家相似的非玩家角色(NPC)。
- 教育和模拟训练:创造历史人物或模拟特定场景,用于教育目的或专业培训,例如医疗模拟和驾驶训练。
常见问题
- ConsisID的生成速度如何?:ConsisID的生成速度受模型复杂性和输入内容的影响,通常情况下可以快速生成高质量视频。
- 是否需要专业知识才能使用ConsisID?:不需要,ConsisID设计为免调优,用户只需提供文本提示即可生成视频。
- ConsisID是否支持多种语言?:目前,ConsisID主要支持中文和英文,未来可能会扩展其他语言支持。
- 生成的视频可以用于商业用途吗?:用户在使用生成的视频时,需遵循相关的法律法规和使用条款。
- 是否可以自定义生成的视频内容?:是的,用户可以通过文本提示自定义人物的动作、表情和背景等元素。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。