SPDL(Scalable and Performant Data Loading)是由Meta AI开发的一款开源数据加载工具,旨在显著提升AI模型的训练效率。该工具基于多线程技术,能够实现高吞吐量的数据加载,同时降低计算资源的消耗。与传统的进程加载方法相比,SPDL的吞吐量提高了2到3倍,并且与Free-Threaded Python兼容,在禁用GIL的环境下还能进一步提升30%的性能。通过异步循环和线程安全的操作,SPDL优化了数据加载过程,支持分布式系统及主流AI框架PyTorch,适用于大规模数据集和复杂的任务。
SPDL是什么
SPDL(Scalable and Performant Data Loading)是由Meta AI推出的开源数据加载工具,旨在提高AI模型的训练效率。它依托于多线程技术,能够实现高吞吐量的数据加载,有效减少计算资源的消耗。与传统基于进程的数据加载方式相比,SPDL提升了2-3倍的吞吐量,并且与Free-Threaded Python兼容,能够在禁用GIL的环境中进一步提升性能。SPDL通过异步循环和线程安全的操作优化数据加载,支持分布式系统和主流AI框架PyTorch,非常适合处理大规模数据集与复杂任务。
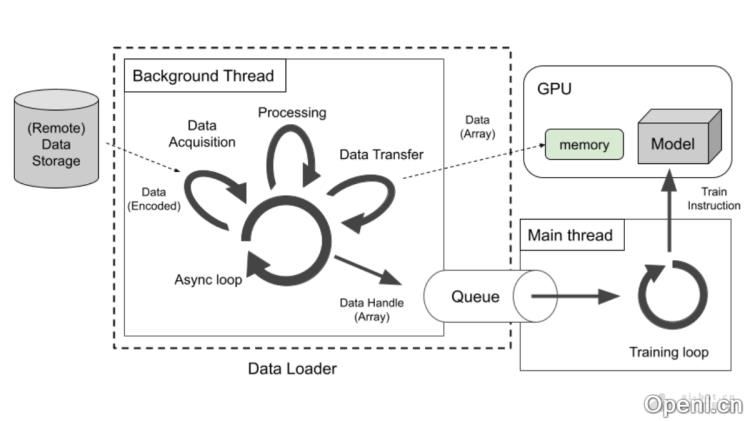
SPDL的主要功能
- 高效的数据加载:采用多线程技术,满足GPU高速计算的需求,减少GPU的空闲时间。
- 低资源占用:SPDL能够以更低的计算资源降低内存和CPU的使用。
- 框架无关性:作为一种框架无关的数据加载解决方案,SPDL能够与多种AI框架兼容使用,包括PyTorch。
- 兼容性:SPDL与Free-Threaded Python兼容,能够在禁用GIL的环境中进一步提高性能。
- 性能监控与优化:提供工具以帮助用户深入了解数据加载过程,进行性能优化。
- 支持分布式系统:SPDL能够在分布式系统中高效工作,适应单GPU以及大型集群,处理复杂任务。
- 预取与缓存技术:基于预取和缓存技术,确保GPU始终有可用数据,减少GPU的空闲时间。
SPDL的技术原理
- 多线程并行处理:利用线程的并行处理,降低进程间通信的开销,提高数据传输速度。
- 异步循环机制:SPDL的核心为异步循环,负责调度新任务与响应已完成任务,实现真正的并发执行。
- 线程安全与GIL释放:SPDL的媒体处理操作是线程安全的,并在执行时释放GIL(Python的全局解释器锁),支持真正的并行执行。
- 流水线抽象:SPDL提供任务执行器,用户能够构建复杂的数据处理流水线。
- 灵活的并发调整:用户可根据数据加载的不同阶段(如数据获取、预处理、传输)灵活调整并发策略,优化整体性能。
- 高效的媒体处理:从零开始实现媒体解码功能,确保在性能关键的代码中线程安全,并释放GIL。
- 异步I/O操作:通过网络存储提供的异步API执行异步I/O操作,提升性能,不受GIL限制。
SPDL的项目地址
SPDL的应用场景
- 大规模机器学习训练:在训练大规模机器学习模型时,SPDL提供高吞吐量的数据加载,确保GPU资源充分利用。
- 深度学习模型训练:深度学习模型能够从SPDL高效的数据处理与加载中获益。
- 分布式训练环境:在分布式训练环境中,跨多个GPU和节点工作,提供一致的高性能数据加载。
- 实时数据处理:对于需要实时数据处理的应用,比如在线推荐系统或实时监控系统,确保数据快速加载与处理。
- 多模态数据训练:涉及图像、文本、音频等多种数据类型的多模态AI模型训练,从SPDL的灵活性和高效性中受益。
常见问题
- SPDL支持哪些AI框架?:SPDL作为框架无关的工具,兼容多种AI框架,包括PyTorch。
- 如何优化SPDL的性能?:用户可以通过调整并发策略和使用性能监控工具来优化SPDL的性能。
- SPDL适用于什么样的数据集?:SPDL特别适合处理大规模数据集和复杂任务。
- SPDL是否支持分布式训练?:是的,SPDL支持在分布式系统中高效工作,适应单GPU和大型集群。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。