产品名称:Phi-4
产品简介:Phi-4是微软推出的14亿参数小型语言模型,在数学等领域的复杂推理以及传统语言处理方面表现出色。Phi-4用数据质量为核心训练重点,大量融入合成数据,提升模型在STEM问答和数学竞赛问题上的表现。Phi-4引入新的训练范式midtraining,增强长文本处理能力,窗口长度可达16K。
详细介绍:
Phi-4是什么
Phi-4是微软推出的14B参数小型语言模型,在数学等领域的复杂推理以及传统语言处理方面表现出色。Phi-4用数据质量为核心训练重点,大量融入合成数据,提升模型在STEM问答和数学竞赛问题上的表现。Phi-4引入新的训练范式midtraining,增强长文本处理能力,窗口长度可达16K。Phi-4在编程任务上表现出色,在HumanEval基准测试中以82.6%的准确率领先其他开源模型(如70B的Llama 3.3和72B的Qwen 2.5)。Phi-4目前在Azure AI Foundry上可用,下周将在Hugging Face上可用。
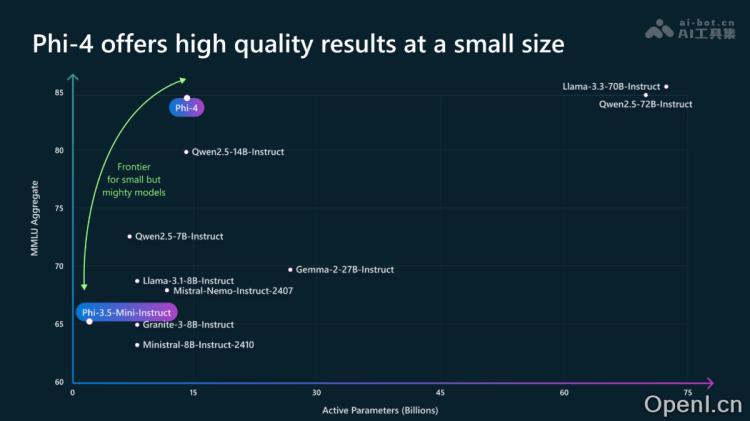
Phi-4的主要功能
- 问答能力:能理解和回答各种问题,尤其在STEM(科学、技术、工程和数学)领域表现出色。
- 数学问题解决:模型在美国数学竞赛AMC 10/12中得分超过90,显示强大的数学推理能力。
- 编程任务:Phi-4在编程任务上表现出色,能理解和生成代码,解决编程问题。
- 长文本处理:基于midtraining阶段,Phi-4能处理长达16K的上下文,保持高召回率。
- 复杂推理:模型在多个基准测试中展现处理复杂推理任务的能力,如MMLU和GPQA。
- 安全交互:Phi-4在后训练中进行安全对齐,确保与用户的交互符合负责任AI原则。
Phi-4的技术原理
- 合成数据训练:Phi-4的训练过程中大量使用合成数据,基于多代理提示、自我修订和指令反转等技术生成,提高模型的推理和问题解决能力。
- midtraining阶段:在预训练和后训练之间加入的midtraining阶段,提升模型处理长文本的能力。
- 长上下文数据选择:从高质量非合成文本中筛选出长于8K tokens的样本,加权超过16K tokens的样本,匹配目标长度。
- 对比学习:用枢轴tokens搜索(PTS)方法,识别对模型输出影响最大的关键tokens,生成高信噪比的对比学习数据。
- 人类反馈:结合人类反馈对比学习(Human Feedback DPO),构造优质的正负样本对,让模型输出更符合人类偏好。
Phi-4的项目地址
- 项目官网:introducing-phi-4
- arXiv技术论文:https://arxiv.org/pdf/2412.08905
Phi-4的应用场景
- 教育辅助:作为教育辅助工具,帮助学生解答STEM领域的复杂问题,提供数学和编程作业的辅导。
- 技术研究:在科学研究中,理解和生成研究论文中的概念和数据,辅助研究人员进行文献综述和数据分析。
- 软件开发:辅助软件开发,包括代码生成、调试和功能实现。
- 智能助手:作为智能助手,理解和响应用户的查询,提供信息检索、日程管理和其他个人助理服务。
- 企业决策支持:分析大量数据,为企业提供市场趋势分析、风险评估和决策支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。