Phi-4:小模型的大智慧——技术详解及简单测评
原标题:开源小模型的大智慧!微软Phi-4技术报告解读与简单测评
文章来源:智猩猩GenAI
内容字数:10088字
微软Phi-4:14B参数小型语言模型的突破
本文概述了微软研究院最新发布的14B参数大型语言模型Phi-4,它在众多大型模型中脱颖而出,并在STEM领域问答能力上超越了GPT-4。其成功秘诀在于对数据质量的极致追求和创新的合成数据生成技术。
1. 数据质量的极致追求:合成数据的重要性
Phi-4的成功离不开对高质量数据的依赖。文章强调数据质量与模型规模同样重要,甚至可能更为关键。Phi系列模型一直重视合成数据,因为它具备结构化和渐进式学习的特点,能够帮助模型更有效地学习,并与推理上下文更好地对齐。与传统的无监督数据集相比,合成数据更易于消化和理解。
2. 合成数据生成方法:多智能体提示与自我修订
Phi-4的预训练主要依赖于约4000B标记的合成数据集。这些数据通过多步骤提示工作流生成,包括多智能体提示、自我修订和指令反转等技术。这些方法弥补了传统数据集的不足,提升了模型的推理和问题解决能力。此外,Phi-4还使用了数千万个经过筛选和增强的有机问题和解决方案,以及来自学术论文、教育论坛和编程教程等高质量的有机数据源。
3. 模型架构与训练过程:4K到16K上下文长度扩展
Phi-4采用仅解码器的Transformer架构,拥有14B参数。其默认上下文长度为4096个标记,并在中训练阶段扩展到16K,这使得模型能够处理更长的文本序列。训练过程持续约10万亿标记,并采用了线性预热和衰减计划等优化策略。中训练阶段主要目标是扩展上下文长度,并使用了更长上下文的数据进行训练,显著提升了长上下文性能。
4. 训练后处理:提升模型可靠性和安全性
训练后处理是Phi-4的关键环节,通过监督微调(SFT)、直接偏好优化(DPO)和关键标记搜索(PTS)等技术,进一步优化模型输出,确保其在推理、编码、对话等任务中的精准性和可靠性。SFT使用约80亿标记的数据进行微调;DPO通过人类偏好数据优化模型输出;PTS通过识别和优化关键标记提升模型推理能力。此外,还进行了幻觉缓解的处理,使模型在不确定时更倾向于拒绝回答。
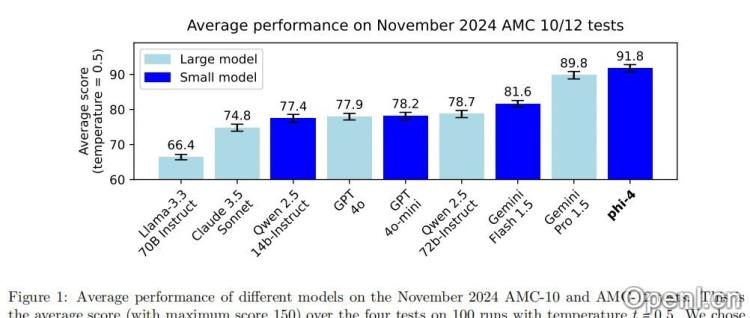
5. 基准测试与性能:超越GPT-4
Phi-4在多个基准测试中表现出色,尤其在STEM问答任务中,甚至在GPQA和MATH上超越了GPT-4。在编码任务中也优于其他开放权重的模型。然而,文章也指出了其在事实知识幻觉和严格遵循详细指令方面的局限性。
6. 安全性与未来展望
Phi-4的开发遵循微软的负责任AI原则,并通过多种安全措施确保其安全性。尽管存在一些弱点,Phi-4的卓越表现证明了小型语言模型的巨大潜力。未来,随着技术的进一步优化,Phi-4有望在更多应用场景中发挥重要作用。
7. 第四届全球自动驾驶峰会
文章最后提及了将于1月14日在北京举办的第四届全球自动驾驶峰会,内容包括开幕式、多个主题论坛和技术研讨会。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。