用近一半数据,有效提升训练集的训练效率
原标题:Scaling Law不总是适用!尤其在文本分类任务中,vivo AI Lab提出数据质量提升解决方法
文章来源:量子位
内容字数:4814字
vivo AI Lab 提出数据质量提升方法
最近,vivo AI Lab研究团队针对文本分类任务,提出了一种名为数据质量提升(DQE)的方法,旨在提高大语言模型(LLM)的准确性和效率。研究表明,扩大训练集的数据量并不总能带来性能提升,尤其在类别界限不清晰的情况下,数据冲突和数据冗余问题可能会加剧。
1. 研究背景
文本分类在情感分析和用户意图识别等任务中具有重要意义,而传统的缩放定律认为大语言模型的性能主要依赖于计算能力、模型参数和训练数据量,这一理论在文本分类任务中并不完全适用。vivo AI Lab团队通过实验发现,使用DQE方法,仅用约一半的数据量,就能有效提高模型的训练效率和准确率。
2. DQE方法设计
DQE方法的设计分为几个步骤:首先,对训练集进行数据清洗,处理缺失值、重复数据和标签不一致的数据。接着,使用文本嵌入模型将文本转换为语义向量,并通过贪婪采样选择最具代表性的数据,以提升数据的多样性。最终,利用采样数据微调大语言模型,并对未采样数据进行预测错误分析。
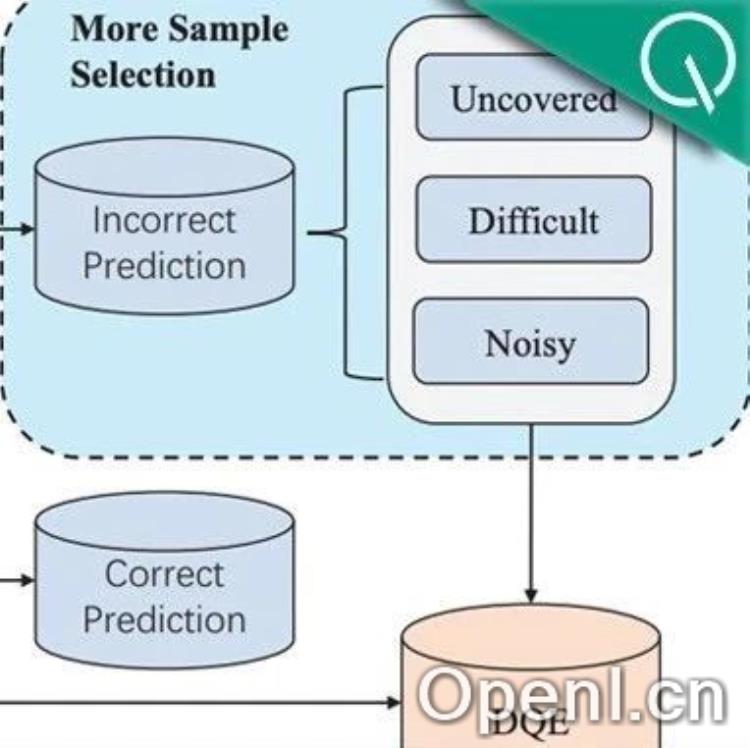
3. 错误数据的分类
在分析预测错误的数据时,作者将其分为三类:Uncovered(未覆盖)、Difficult(困难)和Noisy(噪声)。Uncovered指的是在采样数据中未覆盖的数据,Difficult是指难以学习的样本,而Noisy则是由于标签不一致导致的噪声数据。通过使用GPT-4o,作者进一步辅助判断这些数据的特性。
4. 实验结果与分析
在多个数据集(如MR、CR、IMDb等)上的实验表明,DQE方法在准确率上显著优于全量数据微调,且提高了训练效率。此外,作者还通过t检验分析了模型之间的性能差异,结果显示DQE选择的数据在大多数测试集上均表现出显著的性能提升。
5. 结论与展望
vivo AI Lab团队的研究成果为文本分类任务的数据处理提供了新的思路,强调了数据质量的重要性。未来,进一步优化DQE方法和探索更多数据增强技术将有助于提升AI模型的性能,尤其在情感分析和用户意图识别等关键领域。
论文地址:[https://arxiv.org/abs/2412.06575](https://arxiv.org/abs/2412.06575)
联系作者
文章来源:量子位
作者微信:
作者简介:追踪人工智能新趋势,关注科技行业新突破
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。