INFP是一种音频驱动的头部生成框架,专为双人对话交互而设计,能够在对话音频的引导下自动进行角色的转换,无需手动干预。该框架由两个阶段组成:基于动作的头部模仿阶段和音频引导的动作生成阶段,经过实验和可视化分析,验证了其卓越的性能和有效性。此外,INFP还提出了一个大规模的双人对话数据集DyConv,以促进该研究领域的进一步发展。
INFP是什么
INFP是一种音频驱动的头部生成框架,旨在提升双人对话交互的体验。该系统能够自动识别并转换对话中的角色,省去手动分配角色和角色切换的繁琐过程。INFP由两个主要阶段构成:第一阶段是基于动作的头部模仿,而第二阶段则是音频引导的动作生成。通过实验和可视化结果,INFP显示出其在此领域的优越性和实用性。此外,INFP还推出了大规模双人对话数据集DyConv,以支持相关研究的进步。
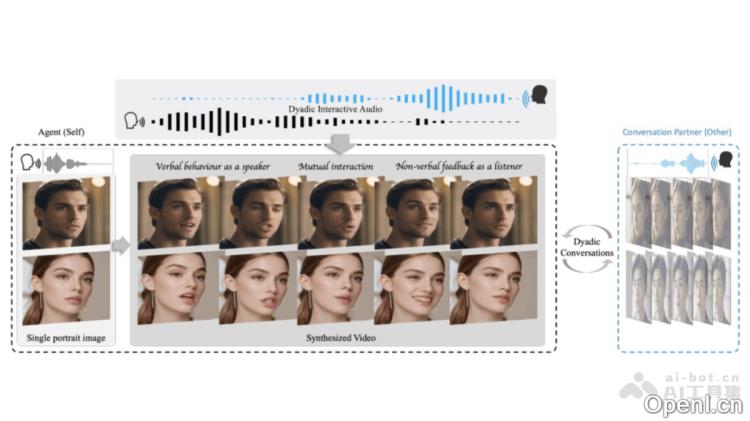
INFP的主要功能
- 自动角色转换:在双人对话中,INFP能够自动识别并切换角色,提升交互的自然性和流畅性,无需用户手动操作。
- 高效轻量:INFP不仅功能强大,且具备轻量化特性。在Nvidia Tesla A10上,其推理速度超过40 fps,支持实时智能代理交互,适用于代理之间或人与代理的沟通。
- 交互式头部生成:INFP的两个关键阶段包括基于的头部模仿和音频引导的生成。第一阶段将真实对话视频中的面部交流行为编码为低维潜在空间,第二阶段则将音频输入映射到这些潜在代码,从而实现音频驱动的头部生成。
- 大规模双人对话数据集DyConv:为推动该领域的研究,INFP推出了DyConv数据集,收录了来自互联网的丰富双人对话样本。
INFP的技术原理
- 基于的头部模仿阶段:在此阶段,框架通过学习将实际对话视频中的面部交流行为映射到低维潜在空间,从而提取出可用于驱动静态图像动画的潜在代码。
- 音频引导生成阶段:在此阶段,框架实现了从输入双通道音频到潜在代码的映射,通过去噪处理,为交互场景提供音频驱动的头部生成。
- 实时互动与风格控制:INFP支持实时互动,用户可以随时打断或回应虚拟形象。此外,INFP还能够提取任意肖像视频的风格向量,实现对生成结果中情绪或态度的全局控制。
INFP的项目地址
INFP的应用场景
- 视频会议与虚拟助手:INFP框架能够实现高度真实感、交互性和实时性,适合于视频会议和虚拟助手等实时场景,提供更自然流畅的交互体验。
- 社交媒体与互动娱乐:在社交媒体和互动娱乐应用中,INFP可用于生成自然表情和头部动作的交互式头像,提升用户的互动体验。
- 教育培训:INFP能够创建虚拟教师或培训师,提供生动且互动的教学体验。
- 客户服务:在客户服务领域,INFP可用于生成虚拟客服代表,提供更加人性化的服务体验。
- 广告与营销:INFP可以用于创建吸引人的虚拟代言人,增强广告和营销活动的互动性和真实感。
- 游戏与模拟:在游戏和模拟环境中,INFP可以创建更加真实和互动的角色,提升游戏的沉浸感和互动性。
常见问题
关于INFP的使用和功能,用户常常会有以下疑问:
- INFP适合哪些平台?:INFP设计适用于多种平台,包括PC和移动设备,能够在多种环境中提供良好的用户体验。
- 如何获取INFP的相关资源?:用户可以通过访问INFP的官方网站和arXiv技术论文获取相关资源和文档。
- 是否需要专业知识才能使用INFP?:虽然INFP的设计考虑到了用户的易用性,但具备一定的技术背景将有助于更好地理解和应用该框架。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。