Hallo3 – 复旦联合百度开源的高动态与真实感肖像动画生成框架
Hallo3是复旦大学与百度公司联合推出的一款基于扩散变换器网络(Diffusion Transformer Networks)的肖像图像动画技术,能够生成极具动态感和真实感的视频。该技术借助于预训练的变换器视频生成模型,成功克服了现有方法在处理非正面视角、动态对象渲染及沉浸式背景生成过程中的挑战。
Hallo3是什么
Hallo3由复旦大学与百度公司共同开发,采用扩散变换器网络技术,专注于肖像图像的动画处理,能够生成高度真实与动态的视频内容。该系统基于经过预训练的变换器视频生成模型,有效解决了当前技术在非正面视角、动态对象渲染和背景生成方面的各种难题。Hallo3运用新的视频骨干网络,设计身份参考网络以确保视频序列中面部特征的一致性,并结合语音音频条件和帧机制,实现由音频驱动的连续视频生成。实验结果表明,Hallo3在生成多角度的逼真肖像方面表现卓越,能够适应复杂的姿势和动态场景,创造平滑且真实的动画效果。
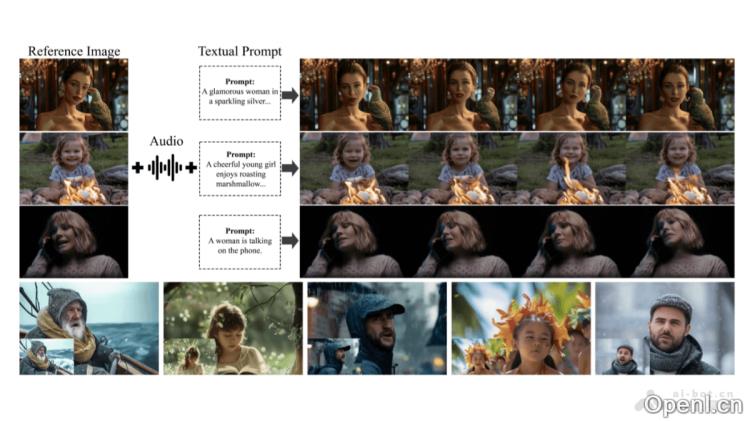
Hallo3的主要功能
- 多视角动画生成:突破传统方法的限制,能够从多种视角(如正面、侧面、俯视或仰视)生成动画肖像。
- 动态对象渲染:有效处理肖像周围的动态元素,如人物手持物品的自然,增强视频的真实感。
- 沉浸式背景生成:创建具有动态效果的背景场景,如篝火或繁忙街道,增强整体的沉浸体验。
- 身份一致性保持:在视频序列中保持肖像的身份一致性,确保长时间动画中面部特征的准确识别。
- 语音驱动的动画:通过语音音频驱动面部表情和嘴唇动作,实现高度同步的自然动画效果。
Hallo3的技术原理
- 预训练的变换器视频生成模型:
- 基础架构:CogVideoX模型作为基础架构,通过3D变分自编码器(VAE)压缩视频数据,将潜在变量与文本嵌入结合,利用专家变换器网络进行处理。
- 条件机制:引入文本提示(ctext)、语音音频条件(caudio)和身份外观条件(cid)三种条件机制,通过交叉注意力(cross-attention)和自适应层归一化(adaLN)整合这些信息。
- 身份参考网络:
- 3D VAE和变换器层:结合因果3D VAE和42层变换器层的身份参考网络,从参考图像中提取身份特征,嵌入去噪潜在代码中,利用自注意力机制增强模型对身份信息的表示和长期保持。
- 特征融合:将参考网络生成的视觉特征与去噪网络特征融合,确保长时间序列中的面部动画保持一致性和连贯性。
- 语音音频条件:
- 音频嵌入:利用wav2vec框架提取音频特征,为每帧生成特定的音频嵌入,并通过线性变换层将其转化为适合模型的表示。
- 交叉注意力机制:在去噪网络中,交叉注意力机制将音频嵌入与潜在编码进行交互,提升生成输出的相关性,确保模型有效捕捉音频信号。
- 视频外推:通过将生成视频的最后几帧作为后续片段生成的输入,利用3D VAE处理帧,实现时间一致的长视频推理。
- 训练与推理:
- 训练过程:分为两个阶段,第一阶段专注于生成具有身份一致性的视频;第二阶段则扩展至音频驱动的视频生成,结合音频注意力模块。
- 推理过程:模型根据参考图像、驱动音频、文本提示和帧进行输入,生成具有身份一致性和嘴唇同步的视频。
Hallo3的项目地址
- 项目官网:https://fudan-generative-vision.github.io/hallo3
- GitHub仓库:https://github.com/fudan-generative-vision/hallo3
- HuggingFace模型库:https://huggingface.co/fudan-generative-ai/hallo3
- arXiv技术论文:https://arxiv.org/pdf/2412.00733
Hallo3的应用场景
- 游戏开发:为游戏角色生成动态肖像动画,使其表现更为自然,提升玩家的游戏体验。
- 电影制作:创造逼真的角色动画,增强电影和动画的视觉表现力及沉浸感。
- 社交媒体:为用户提供动态头像,使个人资料更加生动有趣,提升社交媒体的个性化体验。
- 在线教育:生成虚拟讲师的动画,使在线课程更具吸引力,提升学生的学习兴趣和参与度。
- 虚拟现实与增强现实:在VR和AR应用中创建虚拟角色,提供更为真实的互动体验,增强用户的沉浸感。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。