Search-o1 – 人大联合清华推出自主知识检索增强的推理框架
XX是什么
Search-o1是由中国人民大学和清华大合开发的一种创新型框架,旨在增强大型推理模型(LRMs)在处理复杂问题时的推理能力。该框架结合了代理检索增强生成(RAG)机制与Reason-in-Documents模块,使得LRMs能够在推理过程中动态获取外部知识,从而弥补知识的不足。RAG机制允许模型自主判断何时发起搜索请求,而Reason-in-Documents模块则负责提炼检索到的信息,确保这些信息能够顺畅融入推理链中,进而保持推理的连贯性与逻辑性。Search-o1已在多个复杂推理任务及开放域问答基准测试中展现出卓越的性能,为构建更为可靠和通用的智能系统提供了新的方向。
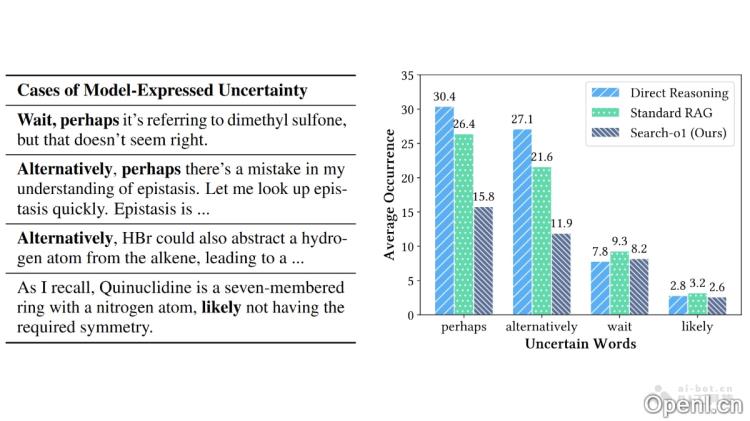
主要功能
- 动态知识检索:在推理过程中,模型能够在遇到知识空白时,主动检索外部知识,支持逐步推理的发展。
- 知识精炼:将获取到的文档信息提炼为简洁且相关的内容,确保这些信息能够无缝融入推理过程,保持推理的连贯性。
- 提升推理准确性:通过补充外部知识,减少因知识不足导致的错误,提高推理的准确性和可信度。
- 多任务适应性:在科学、数学、编程等复杂推理任务及开放域问答中表现优异,展现了广泛的适用能力。
技术原理
- 代理检索增强生成(RAG)机制:
- 自主检索:模型在推理过程中能够自主决定何时生成搜索请求,从而触发检索机制以获取相关的外部知识。
- 动态迭代:在单一推理会话中,检索机制可以多次启动,以满足不同推理步骤的知识需求。
- 特殊符号:搜索请求和检索结果会被特殊符号包围,确保检索过程与推理链的无缝衔接。
- Reason-in-Documents模块:
- 文档分析:基于当前搜索请求、检索到的文档以及以往的推理步骤,深入分析文档内容。
- 信息提取:从文档中提取与当前推理步骤相关的信息,确保信息的准确性和相关性。
- 精炼输出:生成简洁且相关的信息,并将其无缝整合到推理链中,保持推理的连贯性和逻辑一致性。
产品官网
- 项目官网:https://search-o1.github.io
- GitHub仓库:https://github.com/sunnynexus/Search-o1
- HuggingFace模型库:https://huggingface.co/papers/2501.05366
- arXiv技术论文:https://arxiv.org/pdf/2501.05366
应用场景
- 科学研究:在化学、物理学和生物学等科学领域,通过动态检索和整合知识,解决诸如化学反应分析、物理问题求解和生物学问题解答等复杂的科学难题。
- 数学教育:在数学问题的解决和竞赛辅导中,能够检索相关的数学公式、定理和解题技巧,帮助学生逐步推导出复杂数学问题的解决方案,从而提升解题能力。
- 编程开发:在编程任务中,通过检索编程语言的语法、库函数以及代码优化技巧,帮助生成正确的代码并优化现有代码的性能,提高开发效率。
- 开放域问答:在单跳和多跳问答任务中,能够检索相关事实和信息,进行多步推理,准确回答各种复杂问题,提供全面的知识支持。
- 医疗健康:在疾病诊断和治疗方案推荐中,能够检索症状、疾病信息、诊断方法以及最新治疗指南,辅助医生进行准确的诊断并提供最佳的治疗建议,提高医疗决策的科学性。
常见问题
在使用Search-o1时,用户可能会遇到一些常见问题,例如如何有效利用动态知识检索,或者如何在特定任务中优化推理链的连贯性。我们建议用户参考项目官网和技术文档,以获取详细的使用指南和最佳实践。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。