MinMo – 阿里通义实验室推出的多模态语音交互大模型
MinMo是阿里巴巴通义实验室FunAudioLLM团队推出的一款先进的多模态大模型,专注于实现无缝的语音交互体验。它具有约80亿个参数,通过多阶段的训练,基于140万小时的多样化语音数据和广泛的语音任务进行深度学习。MinMo支持根据用户的指令调整生成音频的情感、方言和说话风格,甚至能够模仿特定的音色,生成效率超过90%。此外,MinMo具备全双工语音交互能力,语音到文本的延迟约为100毫秒,而全双工的延迟理论上为600毫秒,实际情况约为800毫秒,从而实现用户与系统之间的双向实时沟通,使得多轮对话更加顺畅自然。
MinMo是什么
MinMo是阿里巴巴通义实验室FunAudioLLM团队开发的一款多模态大模型,旨在提供无缝的语音交互体验。该模型包含约80亿个参数,经过多阶段训练,学习了140万小时多样化的语音数据,涵盖各种语音任务。MinMo能够根据用户的需求调整生成音频的情感、方言和说话风格,并模仿特定音色,确保生成效率超过90%。该模型支持全双工语音交互,语音到文本的延迟约为100毫秒,而全双工交互的理论延迟为600毫秒,实际约为800毫秒,使得用户与系统之间能够实现同时的双向交流,从而使多轮对话更加流畅。
MinMo的主要功能
- 实时语音对话:与用户进行自然、流畅的语音对话,理解语音指令并给出相应的声音回应。
- 多语言支持:具备多语言的语音识别和翻译能力,能够在多种语言环境中顺畅沟通。
- 情感表达:能够根据用户指令生成具有特定情感(如快乐、悲伤、惊讶等)的语音。
- 方言和说话风格:支持生成特定方言(如四川话、粤语等)及特定的说话风格(如快速或慢速)的语音。
- 音色模仿:能够模仿特定音色,使语音交互更加个性化和富有表现力。
- 全双工交互:支持用户与系统同时进行说话和听取,实现更加自然和高效的多轮对话,语音到文本延迟约为100毫秒,全双工延迟理论上为600毫秒,实际约为800毫秒。
MinMo的技术原理
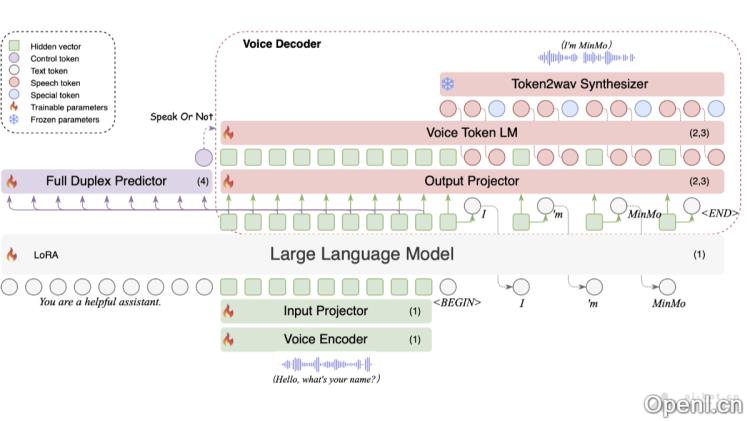
- 多模态融合架构:
- 语音编码器:基于预训练的SenseVoice-large编码器模块,具有强大的语音理解能力,支持多语言语音识别、情感识别和音频检测。
- 输入投影器:由两层Transformer和一层CNN构成,负责维度对齐和降采样。
- 大型语言模型:采用预训练的Qwen2.5-7B-instruct模型,其在多个基准测试中表现出色。
- 输出投影器:单层线性模块,负责维度对齐。
- 语音标记语言模型:使用预训练的CosyVoice 2 LM模块,自回归生成语音标记。
- Token2wav合成器:将语音标记转换为mel频谱图,并进一步转换为波形,支持实时音频合成。
- 全双工预测器:由单层Transformer和线性softmax输出层构成,用于实时预测是否继续响应或暂停处理用户输入。
- 多阶段训练策略:
- 语音到文本对齐:通过大量语音数据和相应的文本标注,训练模型学音与文本之间的映射关系,确保模型能够准确将语音转换为文本,为后续的文本理解和生成奠定基础。
- 文本到语音对齐:使模型学习如何将文本转换为语音,生成自然流畅的语音表达,保持文本的语义信息和情感色彩。
- 语音到语音对齐:进一步提升模型对语音的理解和生成能力,使其能够在语音层面直接进行交互,更好地处理语音的韵律、语调等特征。
- 双工交互对齐:模拟真实的全双工交互场景,训练模型在同时接收和发送语音信号的情况下,准确进行语音识别和生成,优化模型在复杂交互环境下的表现。
MinMo的项目地址
MinMo的应用场景
- 智能客服:提供全天候的多语言语音支持,实时解答客户问题,基于情感识别提供个性化服务,利用全双工对话提升服务效率。
- 智能助手:控制智能家居设备,管理日程,查询信息,推荐个性化内容,提升生活便利性和信息获取的效率。
- 教育领域:辅助语言学习,互动教学提升参与度,根据学习进度提供个性化计划,并通过情感支持鼓励学生学习。
- 医疗健康:进行远程医疗咨询,健康监测提醒,康复训练指导,情感支持疏导,提升医疗服务的可及性和患者体验。
- 智能驾驶:通过语音控制车辆系统,提供实时交通信息和紧急情况指导,利用全双工对话提高驾驶安全性和便利性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。