TimesFM 2.0 – 谷歌研究团队开源的时间序列预测模型
TimesFM 2.0是谷歌研究团队推出的一款开源时间序列预测模型,具备卓越的预测能力,能够处理长达2048个时间点的单变量时间序列,并支持灵活的预测时间跨度。该模型采用纯解码器架构,结合输入修补与修补掩码技术,确保高效的训练与推理,同时具备零样本学习的能力。其预训练数据集涵盖多个领域,使得模型具备良好的泛化能力,广泛适用于零售销量预测、金融市场走势分析等多种场景。
TimesFM 2.0是什么
TimesFM 2.0是谷歌研究团队开发的开源时间序列预测模型,旨在提供强大的预测能力,处理单变量时间序列,支持长度达到2048个时间点的输入,并具备灵活的预测时间跨度。通过采用仅解码器架构,结合输入修补和修补掩码技术,TimesFM 2.0实现了高效的训练与推理,同时支持零样本预测。其丰富的预训练数据集来自多个领域,使其在零售、金融、网站流量预测、环境监测和智能交通等多个行业中表现出色,能有效为用户提供决策支持。
TimesFM 2.0的主要功能
- 卓越的预测能力:能够处理高达2048个时间点的单变量时间序列预测,支持灵活的时间跨度选择。
- 灵活的预测频率选择:用户可根据时间序列的特性,选择预测频率,从而增强预测的适应性。
- 实验性的分位头预测:模型提供了10个分位头,用于生成预测的不确定性估计,虽然这些预测尚未经过校准。
- 丰富的预训练数据集:整合了多个数据集,包括来自TimesFM 1.0的预训练集和LOTSA的附加数据,涵盖住宅用电、太阳能发电和交通流量等多个领域,为模型的训练提供了坚实基础。
- 零样本学习能力:尽管最大训练上下文长度为2048,但在实际应用中,模型可以处理更长的上下文,展现了出色的零样本学习能力。
TimesFM 2.0的技术原理
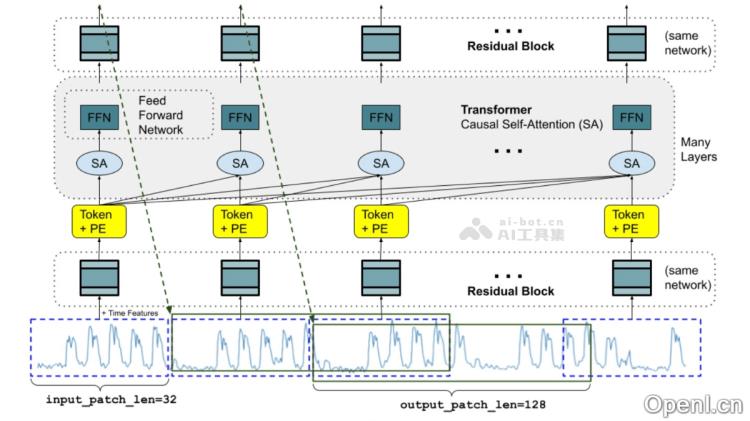
- 纯解码器架构:该模型采用纯解码器架构,能够高效处理时间序列数据,更好地捕捉长距离的时间依赖关系,适合单向预测。
- 时间序列分块与位置编码:模型利用分块处理时间序列,并注入位置编码,通过堆叠的Transformer层提取时间序列中的时间顺序信息与不同时间点的关系。
- 输入修补与修补掩码:通过输入修补和修补掩码技术,模型实现了高效的训练与推理流程,同时支持零样本预测,提升了训练效率和泛化能力。
- 预训练过程:在包含1000亿个真实世界时间点的大规模时间序列语料库上进行预训练,涵盖多个领域和时间粒度的数据,采用自监督学习方法预测序列中的下一个时间点。
- 灵活的输入处理:支持不同长度和频率的时间序列输入,能够适应各种实际应用场景,尽管预训练时最大上下文长度为2048,但在实际应用中可扩展处理更长的时间序列。
- 分位点预测的实验性支持:模型引入了10个分位头,支持用户在单点预测的基础上获取不同分位数的预测值,为不确定性分析提供了新的可能性。
TimesFM 2.0的项目地址
- 项目官网:https://research.google/blog/a-decoder-only-foundation-model-for-time-series-forecasting/
- Github仓库:https://github.com/google-research/timesfm
- HuggingFace模型库:https://huggingface.co/google/timesfm-2.0
- arXiv技术论文:https://arxiv.org/pdf/2310.10688
TimesFM 2.0的应用场景
- 零售行业:可用于销量预测,帮助商家优化库存管理和制定销售策略。
- 金融市场:能够预测股票走势,为投资者的决策提供参考依据。
- 网站运营:可预测网站流量,助力网站优化与资源分配。
- 环境监测:基于历史数据预测环境变化趋势,如空气质量和气候变化,为环境保护和应对措施提供依据。
- 智能交通:通过交通流量历史数据预测未来路况,为城市规划和交通信号优化提供参考,帮助高峰时段管理与减少拥堵。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。