SVFR – 腾讯优图联合厦门大学推出的通用视频人脸修复统一框架
SVFR(Stable Video Face Restoration)是由腾讯优图实验室与厦门大合开发的一个先进框架,专注于视频人脸的广泛修复。该技术融合了视频人脸修复(BFR)、着色及修复任务,基于Stable Video Diffusion(SVD)生成和先验,通过统一的人脸修复框架整合特定任务的信息。SVFR的独特之处在于它引入了可学习的任务嵌入,强化了任务识别能力,并采用了统一潜在正则化(ULR)来促进不同子任务之间的特征共享。此外,为了提升恢复质量和时间一致性,SVFR还引入了面部先验学习和自引用细化策略。
SVFR是什么
SVFR(Stable Video Face Restoration)是腾讯优图实验室与厦门大学共同推出的一个高效框架,旨在实现视频人脸的全面修复。该框架整合了多项技术,包括视频人脸修复(BFR)、着色和缺失部分的修复。SVFR依托于Stable Video Diffusion(SVD)的生成与先验,通过统一的框架有效地融合了各类任务的信息,提升了视频中人脸的清晰度和自然度。
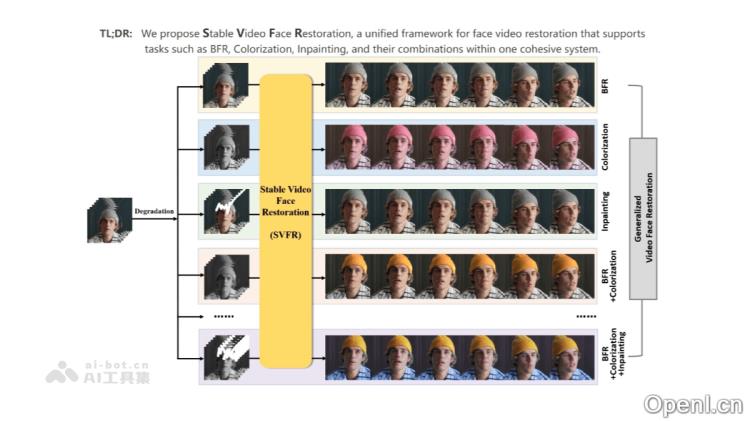
SVFR的主要功能
- 视频人脸修复(BFR):对视频中模糊或损坏的人脸进行增强,使其更加清晰和自然。
- 人脸着色:为黑白或色彩失真的人脸视频添加生动的色彩,提升视觉效果。
- 人脸修复(Inpainting):修复视频中因遮挡或损坏造成的缺失人脸区域,恢复完整的面部细节。
SVFR的技术原理
- 任务整合:SVFR将视频人脸修复、着色和修复任务整合在一个统一框架内,利用各任务之间的互补信息增进整体效果。
- 生成和先验:基于Stable Video Diffusion(SVD),SVFR强化了修复效果,提供强大的生成能力和信息,确保视频中的人脸时间连贯。
- 任务嵌入:引入可学习的任务嵌入,增强模型对特定任务的识别能力,以便更准确地进行修复。
- 统一潜在正则化(ULR):采用ULR方法,促进不同子任务之间的特征共享,提升修复质量。
- 面部先验学习:SVFR通过面部地标等结构先验,嵌入面部结构信息,确保自然的修复效果,避免面部结构失真。
- 自引用细化:在推理阶段,SVFR利用自引用细化策略,参考先前生成的帧,优化当前帧的修复效果,保持时间上的一致性。
SVFR的项目地址
- 项目官网:https://wangzhiyaoo.github.io/SVFR
- Github仓库:https://github.com/wangzhiyaoo/SVFR
- arXiv技术论文:https://arxiv.org/pdf/2501.01235
SVFR的应用场景
- 影视后期制作:对老旧影片中模糊或损坏的人脸进行修复,恢复自然的面部细节,提高观众的观看体验。
- 网络视频内容创作:修复拍摄条件不佳导致人脸质量低下的视频片段,提高整体视频质量,吸引更多观众。
- 数字档案修复:对存储时间较长、质量退化的视频档案中的人脸进行修复,保留珍贵的历史影像资料。
常见问题
- SVFR适合哪些类型的视频修复?:SVFR适用于各种视频修复场景,包括老旧影视作品、网络视频及历史档案。
- 使用SVFR需要什么样的硬件配置?:具体要求取决于视频的分辨率和处理复杂性,通常需要较高的计算能力以确保流畅运行。
- 是否可以处理实时视频?:SVFR主要针对预先录制的视频进行修复,实时处理能力因设备性能而异。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。