DeepSeek-R1论文速读
原标题:比肩最新满血版o1!DeepSeek-R1技术报告解读
文章来源:智猩猩GenAI
内容字数:5671字
DeepSeek-R1:无需大量SFT数据即可媲美OpenAI的推理模型
本文解读了Meta互联网从业者撰写的知乎文章,介绍了DeepSeek团队最新开源的DeepSeek-R1系列模型。该模型在推理能力上取得了显著突破,在多个高难度基准测试中表现优异,达到了与OpenAI-o1-1217和OpenAI-o1-mini相媲美的水平,成为第一梯队推理模型。
1. DeepSeek-R1的核心创新:绕开SFT的强化学习
现有LLM推理模型普遍采用SFT(监督微调)+RL(强化学习)的方式,需要大量标注数据。DeepSeek-R1另辟蹊径,通过巧妙的奖励机制实现了在无需大量SFT数据的情况下,仅依靠大规模强化学习显著提升模型推理能力。
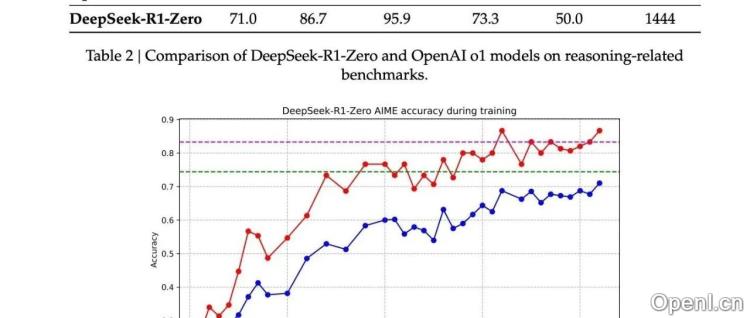
2. DeepSeek-R1-Zero:无SFT的强化学习探索
DeepSeek-R1-Zero是DeepSeek-R1的先锋版本,它直接从DeepSeek-V3-Base模型出发,采用DeepSeek独有的GRPO和简单的奖励机制进行强化学习。奖励机制包括准确性奖励(基于答案匹配和代码执行)和格式奖励(检查CoT过程格式)。尽管方法简单,但DeepSeek-R1-Zero仍取得了接近OpenAI-o1-0912的性能,并展现出模型“进化”的现象,例如输出长度增加,体现了模型自主思考能力的提升。
3. DeepSeek-R1:少量SFT数据冷启动+强化学习
尽管DeepSeek-R1-Zero取得了成功,但其输出可读性差,存在语言混合等问题。DeepSeek-R1在此基础上,加入了少量(数千量级)高质量CoT数据进行SFT冷启动,并增加了语言一致性奖励,进一步提升了模型性能和输出质量。
DeepSeek-R1的训练过程分四个阶段:少量数据冷启动SFT、针对推理场景的RL、拒绝采样和SFT(包含推理数据和非推理数据)、适配所有场景的RL。通过这四个阶段的训练,DeepSeek-R1在保持高推理能力的同时,显著提高了输出的可读性和语言一致性,最终效果与OpenAI-o1-1217不相上下。
4. 高效的模型蒸馏
DeepSeek团队还发现,使用DeepSeek-R1的中间阶段数据(“拒绝采样和SFT”阶段)对小模型进行SFT,无需RL,就能取得令人惊叹的效果,这为低成本高效的模型部署提供了新的思路。
5. 未来改进方向
DeepSeek团队也指出了DeepSeek-R1的一些不足之处,例如通用能力仍需提升,语言混合问题有待解决,对Prompt比较敏感等。未来,他们计划改进模型的通用能力,解决语言混合问题,并提高其在软件工程任务上的表现。
6. 未成功尝试
文章还分享了DeepSeek团队尝试但未成功的方向,例如PRM(程序推理机制)和MCTS(蒙特卡洛树搜索),并分析了这些方法未能成功的原因,体现了团队的开放性和严谨的科研态度。
总而言之,DeepSeek-R1的成功为LLM的训练和应用提供了新的思路,其高效的训练方法和优异的性能,预示着LLM在推理领域将迎来新的发展。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,专注于生成式人工智能。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。