基于世界知识树打造高质量对话数据
原标题:20K合成数据就能让大模型能力飙升!还能实现模型自我迭代,上海AI Lab数据合成新范式
文章来源:量子位
内容字数:3951字
上海AI Lab提出Condor:基于合成数据提升LLM对话能力
本文总结了上海AI Lab研究团队提出的Condor数据合成引擎,该引擎利用合成数据显著提升了大型语言模型(LLM)Qwen的主观对话能力。Condor通过“世界知识树”和“自我反思”机制,高效生成高质量的监督微调(SFT)数据,并展现出模型性能与数据量正相关的特性,尤其在20K数据量级下取得了显著效果,之后增益趋于平缓。此项研究为LLM数据合成提供了新的范式。
1. Condor数据合成引擎:世界知识树与自我反思
Condor数据合成引擎包含两个阶段:Condor Void和Condor Refine。它巧妙地利用单一LLM完成问题合成、回复合成、回复评价和回复改进等多个角色。核心机制在于:
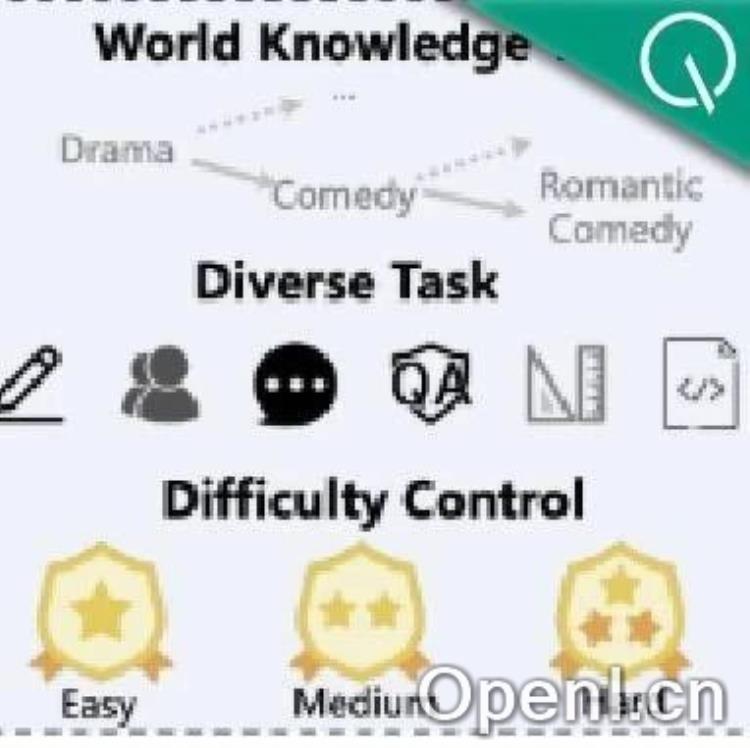
- 世界知识树:Condor通过给定关键词,让模型递归生成子关键词,形成知识树。每个节点作为Tag,用于指导后续数据生成,确保指令的多样性和知识覆盖范围。
- 任务多样性和难度多样性:Condor设计不同问题模板,生成不同类型(日常、角色扮演、创意创作等)和不同难度的问题,提升合成指令的多样性。
- 自我反思:Condor Refine Pipeline引入自我反思策略,模型对初始回复进行评价和修改,迭代优化回复质量,最终生成高质量SFT数据。
2. 实验结果:显著提升主观对话能力
研究人员使用Qwen2.5-72B-Instruct模型进行数据合成,并用Qwen2.5-7B模型进行SFT训练。实验结果表明:使用Condor合成数据训练的模型在主观对话能力上与Qwen2.5-7B-Instruct具有竞争力,并在主流客观评测基准上保持了性能,显著优于其他基线方法。 更重要的是,实验验证了模型性能随着合成数据量增加而提升,在5K到20K数据量区间提升显著,之后增益放缓。
3. 模型自我迭代与性能分析
研究团队还验证了Condor合成数据在模型自我迭代中的作用。使用Condor生成的数据训练7B和72B的基模型,均实现了自我迭代,性能进一步提升。通过对主观评测集按能力维度拆解,发现Condor在Creation、QA和Chat维度上的增益尤为显著。对比分析显示,Condor合成的数据与其他方法相比,能够实现更广泛的知识覆盖,并提升模型回复的拟人化程度和细节。
4. 结论与展望
Condor数据合成引擎为LLM的训练提供了高效、高质量的数据生成方案,成功提升了模型的主观对话能力。 然而,高质量推理数据和多轮对话数据的有效合成策略、真实数据和合成数据的协作配比机制,以及如何突破合成数据的Scaling Law等问题,仍有待进一步研究。Condor的合成数据和训练后的模型已开源,方便社区用户进行体验和探索。
联系作者
文章来源:量子位
作者微信:
作者简介:追踪人工智能新趋势,关注科技行业新突破
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。