本文对几个主流的开源模型系列采用的RL策略进行探讨和总结。
原标题:从DeepSeek到LLaMA,主流开源LLM的RL策略深讨
文章来源:智猩猩GenAI
内容字数:5597字
开源LLM模型的RLHF策略对比
本文总结了DeepSeek、Qwen和LLaMA等主流开源大模型在强化学习自适应微调(RLHF)阶段的不同策略和实现方法。RLHF是提升LLM与人类偏好一致性的关键环节,这些模型在策略选择和工程实现上各有特点。
1. 算法选择:GRPO/PPO与DPO之争
1. 在强化学习算法选择上,目前GRPO、PPO和DPO三者之间没有绝对的优劣之分。DeepSeek系列偏向于使用GRPO,Qwen系列则结合了DPO和PPO(或GRPO),而LLaMA系列则更倾向于使用DPO。
2. DeepSeek早期使用DPO,后转向PPO,最终采用GRPO。GRPO通过估计基线值来优化策略模型,省去了critic model。DeepSeek-V3还引入了self-rewarding策略,让模型能够自我改进。
3. Qwen系列从PPO过渡到DPO,并结合离线和在线训练阶段。Qwen2.5-Coder仅使用离线DPO,结合代码沙箱和LLM-as-judge方法评估代码质量。
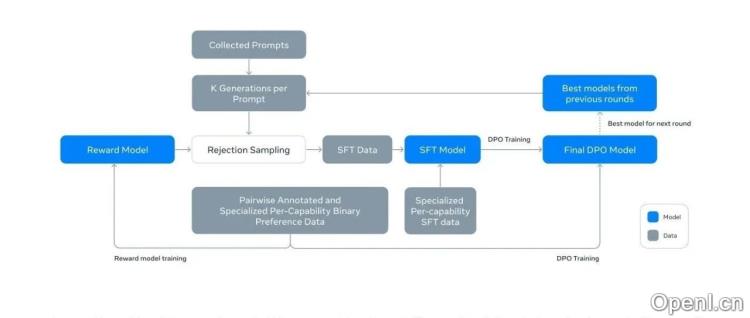
4. LLaMA系列采用迭代式策略,结合Rejection Sampling和PPO(或DPO)进行优化,通过多次采样和选择逐步提升模型性能。LLaMA-3系列则改用DPO,并对Reward Model的训练方法进行了调整。
2. 奖励模型(RM)的重要性
1. 无论采用哪种强化学习算法,奖励模型(RM)都是至关重要的。即使使用DPO,也需要RM进行Rejection Sampling来选择高质量的训练样本。
2. 各个模型在每次更新中都对RM的优化进行了改进,包括rule-based RM和model-based RM的并重,以及利用思维链(CoT)数据来增强RM的可靠性。
3. RL阶段的必要性
1. 简单的监督微调(SFT)已经不足以满足对LLM能力的要求,尤其是在代码生成和数学推理等强推理场景下。
2. RL阶段的训练能够显著提升模型的性能,例如在DeepSeek-V2中,RL阶段的训练显著提升了模型在数学和代码任务上的表现。
3. 然而,RL训练也可能带来“对齐税”,即模型在某些标准基准测试上的性能下降,这需要在模型性能和人类偏好对齐之间进行权衡。
4. 各模型RLHF策略总结
1. **DeepSeek:** 从DPO到PPO,最终采用GRPO,并结合rule-based和model-based RM,以及self-rewarding策略。
2. **Qwen:** 从PPO到DPO,结合离线和在线训练阶段,Qwen2.5-Coder则只使用离线DPO。
3. **LLaMA:** 采用迭代式策略,结合Rejection Sampling和PPO/DPO,逐步提升模型性能。
总而言之,开源LLM模型在RLHF策略上不断探索和改进,未来可能会有更多高效且有效的策略出现,以提升LLM的性能和与人类偏好的一致性。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。