长思维链模型(Long-CoT)对AI-Infra的启发
原标题:DeepSeek R1等长思维链模型对AI-Infra的启发
文章来源:智猩猩GenAI
内容字数:10760字
O1/O3/R1/Kimi 1.5模型对AI推理框架的挑战
本文探讨了O1/O3/R1/Kimi 1.5等大型语言模型(LLM)对AI推理框架和基础设施带来的挑战。这些模型的一个共同特点是使用了长思维链(Long Chain-of-Thought,Long CoT)技术,显著提升了推理能力,尤其在代码和数学方面,但同时也增加了推理成本。
1. Long CoT技术路线
Long CoT技术通过生成更长的推理链来提升LLM的复杂推理能力。DeepSeek R1和Kimi 1.5的对比显示,即使对于简单的1+1=?,Long CoT模型也会产生冗长的中间推理过程,Kimi 1.5的思维链通常更长。
2. O1技术路线(猜测)
基于GPT-4的训练过程,推测O1的训练流程为:预训练+CoT训练(CoT SFT+RLHF)+后期训练(SFT+RLHF)->推理(CoT+摘要)。CoT训练是核心,需要补充CoT数据,这可以通过人工标注、模型蒸馏或人工合成实现。推理过程包含CoT生成和摘要两个环节,目前尚不清楚这两个环节是否由不同的模型完成。
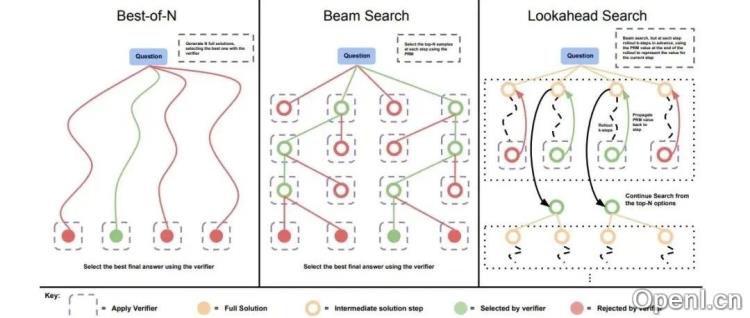
文中讨论了CoT生成过程中的两种方法:Inference-time Scaling Law(通过增加推理时间/维度提升能力)和MCTS(蒙特卡罗树搜索,能够生成复杂的推理样本,但成本高)。
在RLHF训练策略方面,比较了ORM(Optimal Reward Model,仅对最终结果评分)和PRM(Preference Reward Model,对每个中间步骤评分)两种方法。ORM数据需求低,PRM数据标注成本高但上限更高。文章还介绍了MATH-SHEPHERD的自动化数据标注方法。
最后,比较了PPO和GRPO两种RLHF优化算法,GRPO在PPO基础上优化了计算效率。
3. DeepSeek R1
DeepSeek R1基于DeepSeek V3,其技术报告详细介绍了训练细节和失败尝试。主要工作包括:DeepSeek-R1-Zero(仅基于RL实现长CoT);DeepSeek-R1(基于少量高质量CoT数据冷启动,结合RL、SFT训练);以及模型蒸馏,用于提升小模型的推理能力。
报告中还提到了失败的尝试,包括PRM和MCTS,主要由于数据标注成本高和搜索空间过大。
4. Kimi 1.5
Kimi 1.5也开源了技术方案,与DeepSeek R1思路类似,都抛弃了value model,采用多个采样评估生成质量,并基于固定prompt-format指导CoT构造。其训练过程包括预训练、SFT、Long CoT SFT和RL四个部分。
Kimi 1.5的创新之处在于:RL数据生成策略(考虑多样性、难度和可评估性);Long-CoT SFT prompt-format(包含Planning/Evaluation/Reflection/Exploration等认知过程);RL策略(无需显式构建搜索树);以及部署工程上的优化,如Partial Rollouts、长度惩罚和样本采样策略优化等。
5. AI INFRA的需求和挑战
Long CoT模型对AI INFRA提出了新的挑战,包括数据传输(CoT、KV、prompt、logits、checkpoints)、训推加速(混合部署下的任务切换和异步执行)、数据生成(支持多样化采样策略)和评估(支持Code Sandbox等)。
6. 未来展望
未来的研究方向包括:长/短CoT的统一;投机推理的应用;更长文本的支持;以及异构/分离部署。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。