Reasoning Model,RL is all your need !!!
原标题:从字节ReFT到DeepSeek R1,聊聊推理模型Reasoning Model的精巧实现
文章来源:智猩猩GenAI
内容字数:22978字
国产Reasoning Model复现:精巧简洁的RL方案
本文总结了三篇关于Reasoning Model(推理模型)的优秀工作:字节的ReFT、Kimi的K1.5和DeepSeek的R1,它们的核心方法惊人地一致:在Post-Training阶段通过强化学习(RL)来提升模型的推理能力。这展现了国产模型在复现OpenAI等公司成果上的精巧和简洁。
1. 早期猜想与局限性
文章首先回顾了对OpenAI等公司Reasoning Model早期技术的猜想,主要集中在PRM(过程监督奖励模型)和MCTS(蒙特卡洛树搜索)方法。PRM通过分步骤打分来提供更精细的监督信号,MCTS则通过树搜索来探索解空间。然而,PRM需要定义精细的执行步骤,且对数据质量要求高;MCTS则面临搜索空间的问题,节点空间定义也十分困难。这些局限性导致实际复现中很少采用这些方法。
2. 三篇核心工作的比较
文章重点介绍了ReFT、K1.5和R1这三篇工作的核心思路。它们都采用了RL,但在具体实现上各有侧重:
2.1 ReFT: 简化PPO的RL方案
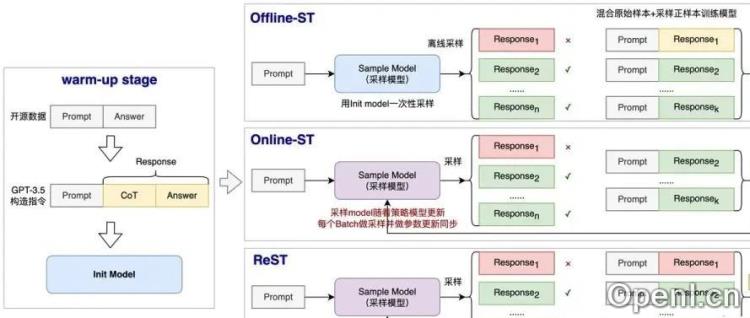
ReFT采用PPO算法,但简化了Reward Model,使用Rule-Base RM(基于规则的奖励模型)来判断答案正确性,并通过参数共享来降低Critic Model的计算复杂度。此外,ReFT还对比了两种Self-Training方法,展现了RL方案的优势。
2.2 Kimi K1.5: 精细化的RL和采样策略
Kimi K1.5在预训练和监督微调后,采用了一种简化的类Policy Gradient方法进行RL训练,避免了Critic Model的计算。其Reward Model设计精细,针对不同问题和训练阶段有不同的策略。此外,Kimi还采用了课程采样和优先采样策略来提高训练效率。
2.3 DeepSeek R1: 激进的纯RL与多阶段优化
DeepSeek R1首先进行了激进的纯RL实验(R1-Zero),但模型存在可读性差等问题。因此,R1在R1-Zero基础上,进行了多阶段优化,包括SFT、RL、增强SFT和增强RL,最终提升了模型的通用性和推理能力。DeepSeek也使用了Rule-Based Reward Model,并增加了语言一致性奖励。
3. 总结
文章总结指出,这三篇工作都通过RL在Post-Training阶段有效提升了模型的推理能力,展现了国产模型在Reasoning Model复现上的成就。其方法精巧简洁,通过清晰的目标设定和对RL的巧妙运用,实现了对复杂问题推理能力的有效提升。最终,文章以“Reasoning Model,RL is all you need”来概括其核心思想。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。