原标题:OpenAI模型突现中文推理:是“偷师”还是AI的语言偏好?
文章来源:小夏聊AIGC
内容字数:1662字
AI模型的“语言偏好”:OpenAI模型偏爱中文引发的思考
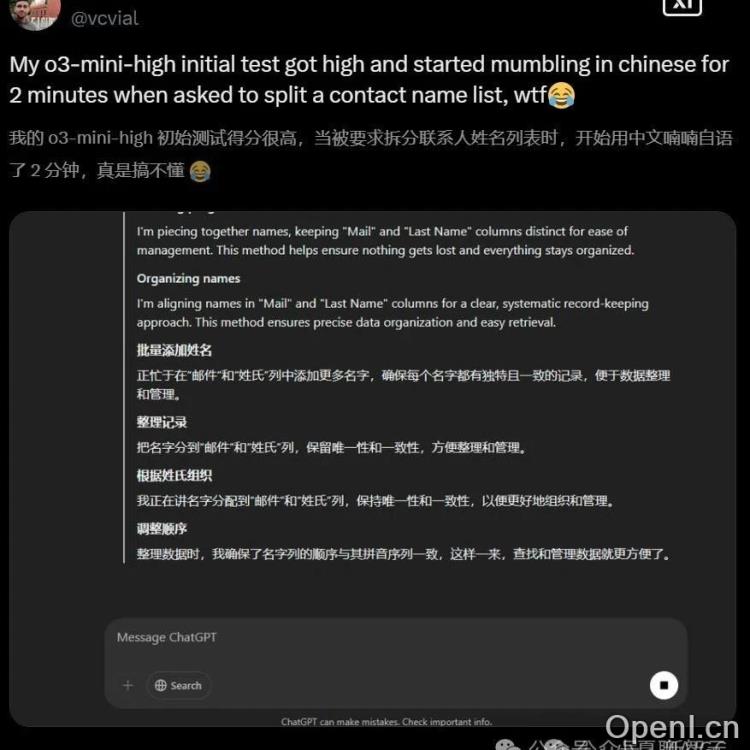
近日,OpenAI的o3-mini-high模型展现出一种令人意外的“语言偏好”:它在推理过程中频繁使用中文,即使面对俄语等其他语言的提问也是如此。这一现象迅速在网络上引发热议,甚至有人戏称中文是“LLM的灵魂语言”。本文将探讨这一现象背后的原因,以及它对AI发展和应用的潜在影响。
“语言混杂”现象并非个例
事实上,AI模型出现“语言混杂”的情况并非首次发生。此前,OpenAI的其他模型,以及谷歌的Gemini等大型语言模型,都曾出现过类似问题,只是混杂的语言有所不同。这表明,这并非某个特定模型的缺陷,而是大型语言模型训练过程中可能存在的一个普遍性问题。
AI模型如何“选择”语言?
那么,为什么AI模型会偏好某种语言呢?专家们给出了多种解释。阿尔伯塔大学的AI研究员Matthew Guzdial指出,模型并不真正“理解”语言,而是将语言视为一系列的tokens(标记)。模型的处理过程是基于这些tokens的统计关联,而非语言本身的语义。因此,在训练数据中,如果某种语言的tokens出现频率更高,或者在特定任务中表现更优,模型就可能更倾向于使用这种语言。
Hugging Face的工程师Tiezhen Wang则认为,这可能与模型在训练过程中建立的特殊关联有关,类似于人类的双语思维模式。例如,中文在某些特定领域,比如数算方面,可能拥有更高效的表达方式,从而使得模型在处理相关任务时更倾向于使用中文。
此外,有人推测,中文的简洁性可能在强化学习中获得更多奖励,因为更短的表达方式可能意味着更高的效率。DeepSeek的研究也支持了这一观点,他们发现强化学习提示词涉及多种语言时,容易出现语言混杂,并通过引入“语言一致性奖励”来缓解这个问题。
“语言偏好”对AI应用的影响
AI模型的“语言偏好”对实际应用可能带来一些挑战。对于不熟悉中文的用户来说,模型使用中文进行推理可能会造成理解上的困难,甚至可能导致错误答案。因此,如何确保AI模型在不同语言环境下都能保持一致性和准确性,是一个重要的研究方向。
未来的研究方向
目前,“语言混杂”问题仍然是AI领域的一个挑战。DeepSeek等研究团队已经开始尝试通过改进训练方法和奖励机制来解决这个问题,但仍需要进一步的研究和探索。未来的研究应该关注如何更好地理解和控制AI模型的语言行为,从而构建更加可靠、可解释和易于使用的AI系统。
OpenAI CEO奥特曼对此事的回应也值得关注,他表示OpenAI没有计划DeepSeek,并对自身技术的领先地位充满信心。这或许也反映了大型语言模型领域竞争的激烈程度,以及对技术突破的持续追求。
联系作者
文章来源:小夏聊AIGC
作者微信:
作者简介:专注于人工智能生成内容的前沿信息与技术分享。我们提供AI生成艺术、文本、音乐、视频等领域的最新动态与应用案例。每日新闻速递、技术解读、行业分析、专家观点和创意展示。期待与您一起探索AI的无限潜力。欢迎关注并分享您的AI作品或宝贵意见。
相关文章

全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。