从不同的视角对LLMs进行讨论,包括训练与推理方法、信息检索、安全性、多领域与语言文化的融合以及数据集的使用。
原标题:495篇参考文献!北交大清华等高校发布多语言大模型综述
文章来源:量子位
内容字数:10338字
大模型多语言能力综述:挑战与未来
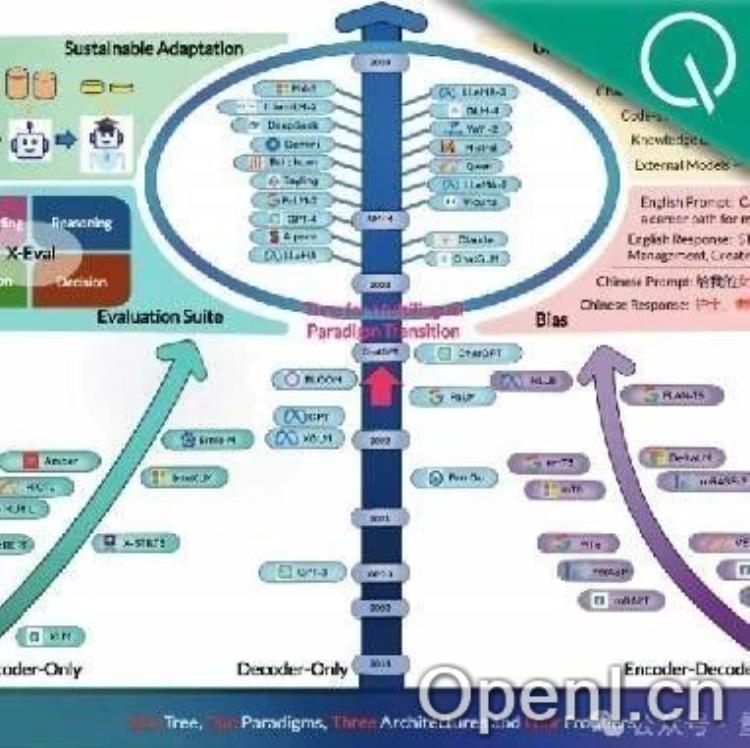
本文总结了北京交通大学等团队发表的关于大模型多语言能力的综述论文 (A Survey on Large Language Models with Multilingualism: Recent Advances and New Frontiers) 的核心内容。该论文全面回顾了大模型在多语言能力上的最新进展、面临的挑战以及未来的发展方向,参考文献多达495篇。
1. 大模型多语言能力的局限性
尽管大模型取得了显著进展,但在多语言场景下,尤其是在低资源语言方面,仍存在很大局限性。主要原因在于训练数据的语言分布高度不平衡,不同语言的数据质量差异较大。这导致模型在不同语言上的表现参差不齐,并面临数据匮乏、知识冲突、知识类型单一等问题。
2. 训练方法
论文将多语言大模型的训练方法分为两类:从头开始训练和持续训练。从头训练利用所有可用数据进行训练,并使用语言采样算法控制每种语言的重要性;持续训练则在基础模型上进行更新,降低了训练成本和资源需求。尽管两种方法都取得了进展,但低资源语言、知识冲突等问题仍然存在。未来研究需要探索优化多语言表示空间、定制化模型架构以及LLMs的终身学习能力。
3. 多语言推理策略
论文探讨了多种多语言推理策略,包括直接推理、预翻译推理、多语言思维链 (CoT) 和代码切换 (Code-switching) 处理。直接推理效率高,但并非适用于所有模型;预翻译推理将多种语言翻译成高资源语言再进行推理;多语言CoT能够处理更复杂的推理任务;代码切换处理则需要应对语言在句子中切换的复杂情况。多语言检索增强 (RAG) 方法可以缓解低资源语言的翻译问题,但构建适用于低资源语言的检索器仍然是一个挑战。
4. 多语言信息检索
论文探讨了大模型在多语言信息检索中的应用,包括利用大模型生成合成数据训练检索模型,以及使用大模型作为zero-shot重排序器。基于LLM的embedding模型在检索任务中表现出色,但索引和搜索过程的高延迟以及计算资源的高需求仍然是挑战。低资源语言中LLM的生成能力不足也限制了其作为可靠知识来源的应用。
5. 安全性
论文分析了大模型在多语言场景下的安全问题,包括“越狱”攻击等。越狱攻击方法包括贪婪坐标梯度(GCG)越狱、基于提示的越狱和多语言越狱。防御方法包括对模型进行安全指令微调和审计输入提示。未来研究需要探索针对LLMs多语言能力的越狱攻击以及提高模型在多语言场景下的鲁棒性。
6. 领域特定场景
论文探讨了大模型在医学和法律等领域特定场景中的应用。这些领域存在数据稀缺和翻译问题,低资源语言的表现不足仍然是主要挑战。未来需要考虑领域特定知识和语言文化差异,并解决机器翻译在处理领域特定术语时的不足。
7. 数据资源、基准与评估
论文总结了现有的大模型多语言训练数据集和基准数据集,并分析了各种评估方法。英语资源占主导地位,低资源语言的数据质量较低,这需要、公司和研究人员共同努力,构建更全面和权威的多语言基准。
8. 偏见与公平性
论文指出,大模型在多语言场景中存在语言偏见和人口偏见,这需要在模型训练和评估中加以考虑,以促进语言公平。
9. 结论与未来方向
论文总结了大模型多语言能力的关键模块及其最新进展,并展望了未来的研究方向,包括可持续训练范式、通用推理范式、面向实际的评估方法以及多语言偏见影响的解决。
联系作者
文章来源:量子位
作者微信:
作者简介:追踪人工智能新趋势,关注科技行业新突破
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。