已在GitHub开源
原标题:成本不到150元!李飞飞等26分钟训出个推理模型,媲美o1和R1,秘诀:用蒸馏
文章来源:量子位
内容字数:5587字
斯坦福团队仅用150元训练出媲美OpenAI o1的推理模型s1
近日,来自斯坦福大学、华盛顿大学、艾伦人工智能实验室等机构的研究人员,在AI教母李飞飞的带领下,推出了一款名为s1的推理模型,其性能可与OpenAI o1和DeepSeek-R1相媲美,然而训练成本却低至150元人民币左右。这一突破性成果引发了广泛关注,其核心在于巧妙地运用模型蒸馏技术。
1. s1模型的低成本训练秘诀:模型蒸馏
s1团队利用阿里通义团队的Qwen2.5-32B-Instruct作为基础模型,通过蒸馏谷歌DeepMind的推理模型Gemini 2.0 Flash Thinking实验版,最终得到了s1模型。整个训练过程仅需16个英伟达H100,耗时26分钟,云计算成本不到50美元。这种极低的成本得益于模型蒸馏技术,它能够将大型模型的知识迁移到较小的模型中,从而降低训练成本和计算资源需求。
2. 精心设计的数据集s1K
为了训练s1,研究团队创建了一个包含1000个精心挑选问题的s1K数据集。这些问题涵盖数学、科学等多个领域,并附有答案以及Gemini 2.0 Flash Thinking实验版的思考过程。数据集的筛选过程严格遵循质量、难度和多样性原则,确保数据的有效性和代表性。
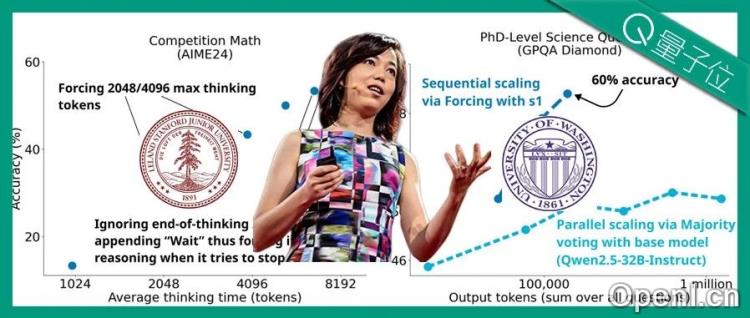
3. 创新的顺序Scaling方法:budget forcing
s1团队专注于Test-time Scaling的顺序Scaling方法,并提出了一种名为“budget forcing”的解码时间干预方法。该方法通过添加“end-of-thinking token分隔符”和“Final Answer”来控制模型思考token的数量上限,并通过禁止生成“end-of-thinking token分隔符”和添加“wait”词来控制下限,从而引导模型进行更深入的推理和迭代细化。 研究还对比了其他方法,例如条件长度控制方法和拒绝抽样,最终证明budget forcing在控制、缩放和性能指标上表现最佳。
4. s1模型的性能表现
在AIME24、MATH500和GPQA Diamond三个推理基准测试中,s1-32B的表现与OpenAI o1和DeepSeek-R1不相上下,尤其在MATH500上取得了93.0的优异成绩。研究发现,虽然budget forcing可以提高模型性能,但过度抑制思考会导致模型陷入死循环。s1模型的样本效率极高,仅用1000个样本训练就达到了接近Gemini 2.0 Thinking的性能。
5. 研究结论与未来展望
s1模型的成功证明了模型蒸馏和Test-time Scaling的巨大潜力,为构建高性能、低成本的推理模型提供了新的思路。该研究也揭示了频繁抑制思考可能导致模型陷入死循环的问题。未来,研究团队将继续探索更有效的Test-time Scaling方法,推动大模型技术的进一步发展。 s1模型的开源也为学术界和工业界提供了宝贵的资源。
联系作者
文章来源:量子位
作者微信:
作者简介:追踪人工智能新趋势,关注科技行业新突破
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。