本篇讲讲deepseek在MoE上的演进过程。
原标题:Deepseek技术解读3:MoE的演进之路
文章来源:智猩猩GenAI
内容字数:15411字
DeepSeek MoE模型演进解读
本文总结了DeepSeek在Mixture-of-Experts (MoE)模型上的演进过程,从DeepSeekMoE (V1)到DeepSeek V3,持续在MoE技术路线进行创新。文章结合论文和源码,深入浅出地解释了MoE的发展历程以及DeepSeek的改进。
1. MoE发展历程回顾
MoE的概念最早于1991年提出,其基本框架至今沿用:由专家网络、门控网络和选择器三部分组成。专家网络负责处理特定子任务;门控网络根据输入,为每个专家分配权重;选择器根据权重选择专家,并融合其输出结果。Google在Transformer时代推动了MoE的发展,其GShard工作将模型规模扩展到600B,并引入了Transformer MoE层设计和负载均衡损失,以解决专家负载不均衡问题。负载均衡损失通过近似计算每个专家接收到的token比例来实现,保证了其可微性,并能通过梯度更新进行优化。
2. DeepSeekMoE (V1)的改进
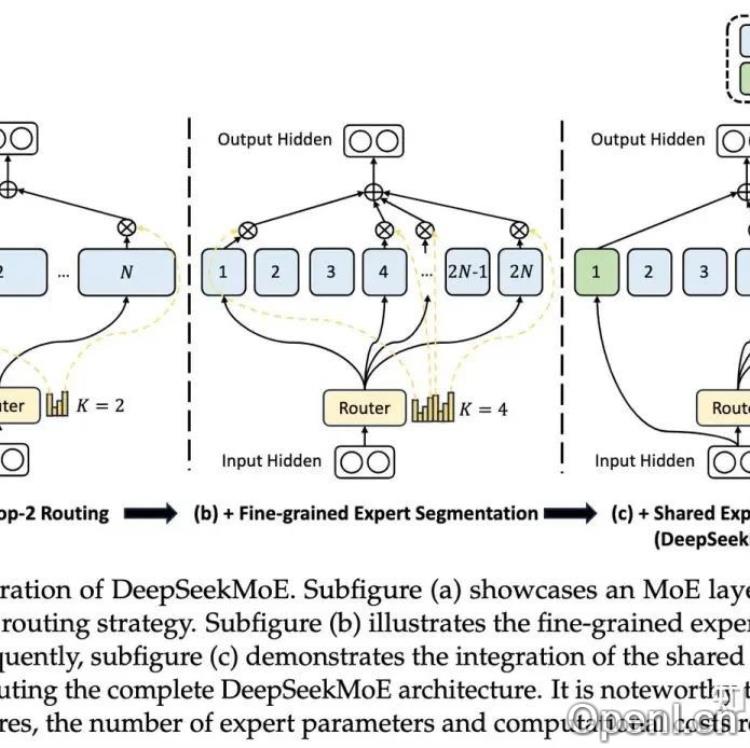
DeepSeek V1针对现有MoE模型的知识混合性和知识冗余性问题,提出了两项改进:细粒度专家分割和共享专家隔离。细粒度专家分割通过分割FFN中间隐藏维度来增加专家数量,提高知识分解的精度;共享专家隔离则将部分专家作为共享专家,用于捕获不同上下文中的共同知识,减轻路由专家之间的冗余。V1版本还引入了专家级负载损失和设备级负载损失,用于平衡专家和设备间的计算负载。
3. DeepSeek V2的改进
DeepSeek V2在负载均衡方面做了三方面升级:1. 设备受限的专家路由机制,限制每个token激活的专家最多分布在M个设备上,降低通信成本;2. 增加通信负载均衡损失,平衡设备接收端的通信负载;3. 设备级Token丢弃策略,在训练阶段丢弃部分token以平衡设备计算负载。在推理阶段,为了保持一致性,保留部分样本不做token丢弃。
4. DeepSeek V3的改进
DeepSeek V3延续了细粒度专家和共享专家设计,并在门控网络和负载均衡方面做了改进:1. 将门控网络的softmax函数替换为sigmoid函数,提升了在高维度专家数量下的区分度;2. 去除了辅助损失,通过动态调节每个专家的bias来实现负载均衡;3. 引入了sequence粒度的负均衡损失,平衡单个sequence的token分配。
5. DeepSeek MoE演进总结
DeepSeek MoE模型的演进过程体现了对专家专业化、负载均衡和效率的持续追求。从V1的细粒度专家分割和共享专家隔离,到V2的通信优化和V3的无辅助损失负载均衡,DeepSeek不断改进MoE模型,提升其性能和效率。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。