关于zero-rl的碎碎念和想法
原标题:复现DeepSeek Zero的RL调参经验
文章来源:智猩猩GenAI
内容字数:7366字
智猩猩DeepSeek大解读:基于Base模型的强化学习
本文总结了haotian在知乎发表的文章,探讨了基于Base模型的强化学习(RL)方法,相较于传统的cold-start-SFT->RL流程,作者更推崇直接在Base模型上进行RL。
1. 基于Base模型的RL的理论优势
1.1 作者将PPO算法解释为贝叶斯推理,并推导出残差能量模型的形式。这使得问题转化为如何高效地从最优分布中采样。方法包括:使用带参数的策略逼近最优分布(方法1,即传统的RL方法及其变种);使用高效的MCMC采样方法从最优分布中采样(方法2)。方法1除了传统的RL方法,还可以使用其他能量模型的参数估计方法。
1.2 过去基于SFT模型的RL效果不佳的原因在于Base模型的质量和RL搜索空间巨大,导致优化复杂度高。但随着预训练模型的改进(例如加入更多推理数据),在Base模型上进行zero-RL变得更可行且有效。
2. 基于Base模型的RL的实践挑战
2.1 LLM的RL与传统RL不同,LLM产生响应并获得奖励的过程缺乏与环境的多步交互,更像是一个bandit问题。并且,LLM本身经过预训练和微调,并非纯粹的预训练模型。
2.2 传统RL的技巧在LLM上适用性存疑。许多传统RL技巧是在随机初始化模型上使用的,LLM的预训练特性使得这些技巧的必要性降低。
2.3 除了RL,其他生成模型的优化方法和MCMC采样也可能适用于LLM,同样需要评估传统技巧的适用性和必要性。
3. 基于Base模型的RL的实际指导意义
3.1 直接在Base模型上进行RL,相当于用带参数的分布拟合最优分布。这为Base模型的优化提供了新方向:分析最优分布采样样本的模式和效果,修正Base模型的数据分布,提升数据分布覆盖率,纠正模型的顽固特性。
3.2 基于Base模型RL得到的答案更贴合Base模型的分布特征,因此基于此数据集进行SFT,应该能得到更好的Instruction模型。
4. zero-RL的复现关键点
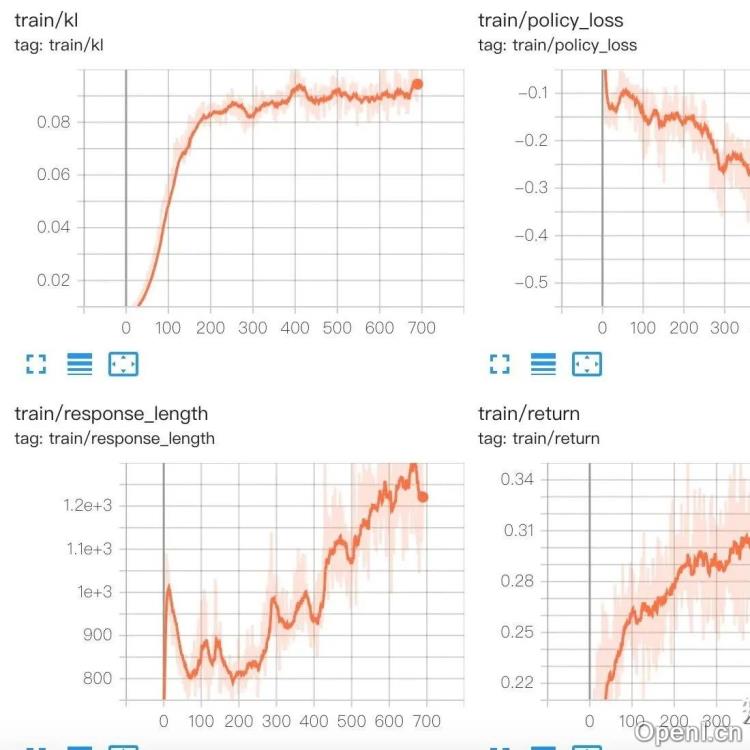
4.1 训练稳定性:需要稳定训练上千个步骤,而非仅仅几个步骤。
4.2 奖励和响应长度的同步增长:如果响应长度不增长,则会退化为传统的短文本Instruction模型的RL,效果有限。
4.3 rule-verified的奖励模型:使用rule-verified的PPO验证至关重要。如果无法实现持续增长,则使用更复杂的奖励模型(例如BT-RM)的优化将更加困难。
4.4 与现有模型的对比:在32B模型上达到与DeepSeek-R1技术报告中Qwen-25-32b-zero相当的效果,是一个可比的基线。
5. 实验结果与结论
5.1 在7B-32B模型上的实验表明,不同的RL算法差异不显著,超参数调整(例如学习率、预热步数)影响有限。
5.2 KL约束会限制模型的探索,在Base模型上的RL,早期探索更为重要。移除KL约束后,模型表现更好,reward和response长度同步增长。
5.3 Prompt模板对结果影响较大,不合适的模板可能训练出类似Instruction风格的模型。
5.4 最朴素的方法(例如Reinforce)可能最有效。
6. 未来展望
6.1 结合环境交互的RL框架是一个重要的方向,但需要构建合适的环境。
6.2 其他生成模型的优化/采样方法(例如EBM)也值得探索。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。