本文主要介绍我们在弱teacher上蒸馏的经验和在zero-rl的一些新的结果和思考。
智猩猩AI新青年讲座:深度推理模型专题
本文总结了知乎文章“智猩猩AI新青年讲座最新增设DeepSeek R1与推理模型专题”的主要内容,该文章探讨了近期深度推理模型的突破性进展,特别是DeepSeek R1系列模型的优秀表现以及Zero-RL范式的革新。
1. DeepSeek R1及近期深度推理模型进展
近期,多个深度推理模型井喷式发布,包括DeepSeek-R1、Kimi1.5和Baichuan-M1等。DeepSeek R1系列通过蒸馏强Teacher模型到Qwen25全家桶,显著提升了推理能力,且训练成本仅需4500美元,1.5B的小模型推理能力超越了o1-preview。Zero系列则实现了范式转移,省去了SFT阶段,降低了人工数据标注成本。DeepSeek R1和Kimi1.5则采用传统的pretrain→SFT→RL方法,在成本和效果上取得了平衡。值得注意的是,R1模型不仅理科能力强,创作能力也十分出色,引发了关于推理能力是否提升通用能力的关键因素的讨论。
2. RedStar项目及深度推理蒸馏经验
RedStar项目探讨了深度推理数据规模、模型规模、难度等级以及多模态对推理能力的影响。研究表明,更高难度的数据能更显著提升推理能力;模型规模越大越好;盲目增加数据量提升有限;中等尺寸的RL-scaling能进一步提升效果;仅使用code数据训练也能提升math能力;深度推理模型在通用评测上的表现相对较好,但会影响指令遵循能力;多模态深度推理需要考虑视觉感知层面的深度推理。
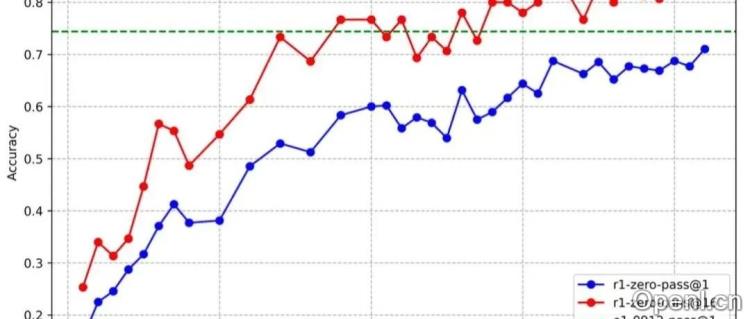
3. DeepSeek-Zero带来的启发
DeepSeek-Zero的成功训练带来了新的想象空间。文章探讨了如何从policy-gradient+kl-constraint的角度出发,得到最优分布,并通过MCMC采样或RL方法获取最优分布的样本。与传统的pretrain→SFT→RL流程相比,Zero-RL省去了SFT阶段,能够更好地优化base-model,提升RL-scale的效果和收敛效率。文章也提出了Zero-RL需要解决的关键问题,例如什么样的基座模型适合Zero-RL,如何选择RL算法等。
4. RL-Scaling的未来方向
文章展望了RL-scaling的三个阶段:粗犷式RL、精细式RL和协同式RL。协同式RL将涉及多模态协同优化、混合范式协同训练和系统级协同部署等技术。文章还强调了构建适用于LLM的Gym环境、难度分级的prompt以及已有数据的可验证任务生成的重要性。
5. 总结
本文总结了深度推理模型的最新进展,重点介绍了DeepSeek R1和Zero-RL的突破性成果,并对未来深度推理模型的发展方向进行了展望。文章认为,推理能力的提升可能是提升通用能力的关键,而更强的Teacher模型能够蒸馏出更强的Student模型。 同时,Zero-RL以及基于MCMC采样的方法为优化base-model和提升RL-scale提供了新的思路。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。