本文介绍了 MiniMax-01 系列模型。
原标题:MiniMax-01技术报告解读以及与DeepSeek-V3对比
文章来源:智猩猩GenAI
内容字数:3851字
MiniMax-01:突破长上下文处理瓶颈的大模型
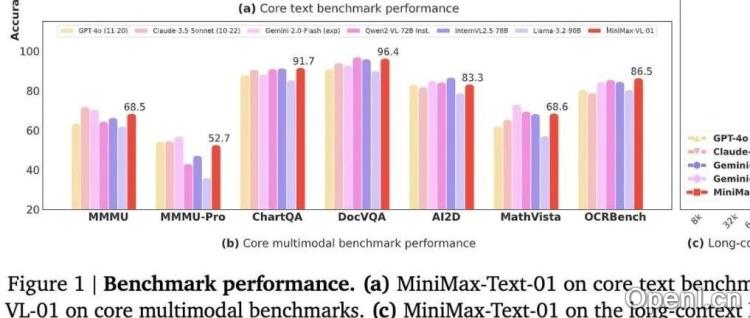
本文介绍了字节跳动研发的MiniMax-01系列模型,包括文本模型MiniMax-Text-01和多模态模型MiniMax-VL-01。该系列模型旨在克服现有大语言模型(LLM)和视觉语言模型(VLM)在长上下文处理方面的局限性,并取得了显著进展。
1. 核心创新:线性注意力机制与高效扩展
MiniMax-01的核心创新在于采用线性注意力机制,而非传统的softmax注意力机制。线性注意力机制具有线性时间复杂度,更适合处理长序列。具体而言,MiniMax-01使用了闪电注意力(Lightning Attention),它通过将注意力计算分为块内和块间两部分,分别使用左乘积和右乘积进行计算,避免了缓慢的累积和操作,从而实现了理论上的线性复杂度,并显著提升了长序列处理速度。
为了弥补线性注意力机制在检索能力上的不足,MiniMax-01还探索了混合架构(Hybrid-Lightning),即每隔8层用softmax注意力层替换闪电注意力层。实验结果表明,混合架构在检索和推理任务上均优于纯softmax注意力模型。
2. 混合专家(MoE)架构的优化与高效训练
MiniMax-01采用了拥有32个专家和4560亿参数的MoE架构。为了解决MoE训练中的路由崩溃问题,MiniMax-01采用全局路由策略,实现负载均衡,减少token丢弃率。此外,MiniMax-01还对专家权重和数据并行性进行了精细划分,设计了专家张量并行(ETP)和专家数据并行(EDP)进程组,以实现存储和计算强度的最佳平衡。
MiniMax-01针对闪电注意力和MoE架构重新设计了训练框架,采用专家并行(EP)和专家张量并行(ETP)来最小化GPU间通信开销。为了支持无限扩展的上下文窗口,MiniMax-01设计了变长环注意力(Varlen Ring Attention)和改进的线性注意力序列并行(LASP)算法。此外,还实现了针对闪电注意力推理的CUDA内核优化,模型浮点运算利用率(MFU)超过75%。
3. 高效的推理框架
MiniMax-01的推理框架优化策略包括:批量内核融合,减少中间结果存储;分离的预填充和解码执行,提高计算效率;多级填充,最小化填充开销;以及利用NVIDIA cuBLAS库和张量内存加速器(TMA)的异步操作,提高计算效率。
4. 长上下文训练策略
MiniMax-01采用数据打包技术和三阶段训练方法,逐步将上下文窗口扩展到100万token,并在推理阶段外推到400万token。训练过程包括短上下文训练、扩展上下文训练、短上下文偏好优化、长上下文偏好优化以及在线强化学习等阶段。
5. 与DeepSeek-V3的对比
MiniMax-01和DeepSeek-V3都是致力于突破LLM性能瓶颈的模型。MiniMax-01更注重长上下文处理能力,而DeepSeek-V3在数学和编码任务上表现出色,并在长上下文理解方面也展现出强大的能力。两者都采用了MoE架构和先进的训练策略。
6. 总结
MiniMax-01系列模型通过线性注意力机制、混合架构、优化的MoE架构以及高效的训练和推理框架,在长上下文处理能力方面取得了显著突破,为大语言模型的发展提供了新的方向。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,专注于生成式人工智能。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。