PIKE-RAG – 微软亚洲研究院推出的检索增强型生成框架
PIKE-RAG是什么
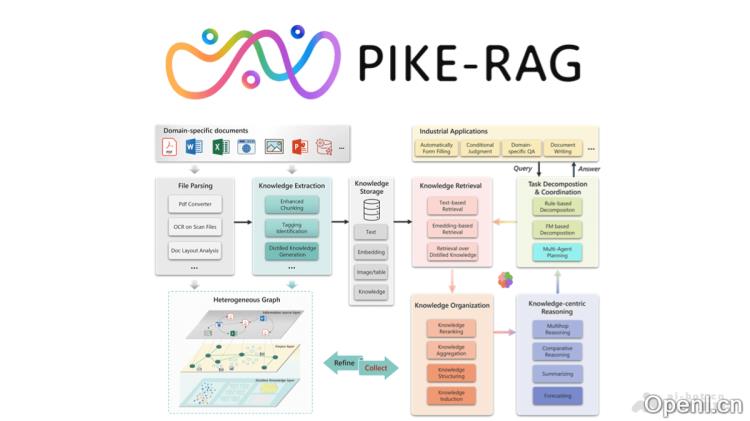
PIKE-RAG(sPecIalized KnowledgE and Rationale Augmented Generation)是由微软亚洲研究院开发的一种检索增强型生成框架,旨在克服传统RAG系统在复杂工业应用中的不足。该框架通过提取、理解和应用专业知识,构建连贯的推理逻辑,从而指导大型语言模型(LLM)生成更为准确的回答。PIKE-RAG采用知识原子化(Knowledge Atomizing)技术,将知识细分为小的原子单元,以问题的形式存储,便于高效检索和组织。此外,PIKE-RAG还引入了多智能体规划模块,能够在处理创造性问题时,从多个视角进行推理和规划。
PIKE-RAG的主要功能
- 专业知识提取与理解:从多样的数据源中提取特定领域的知识,转化为结构化的知识单元,为复杂问题提供准确的知识支持。
- 推理逻辑构建:通过动态任务分解和知识感知的推理路径规划,逐步构建连贯的推理逻辑,引导语言模型生成准确的答案。
- 多跳问题处理:运用知识原子化和任务分解,将复杂问题拆分为多个原子问题,逐步解决多跳推理任务。
- 创造性问题解决:引入多智能体系统,从多个角度进行推理和规划,激发创新性解决方案。
- 分阶段系统开发:根据任务复杂性,支持从基础的事实性问题到高级的创造性问题的分阶段开发,逐步提升系统能力。
PIKE-RAG的技术原理
- 知识原子化:将文档中的知识分解为细粒度的“原子知识”,以问题形式存储。原子知识作为检索的索引,能够更高效地匹配用户问题,提高知识检索的精度。
- 知识感知任务分解:动态地将复杂问题分解为多个原子问题,并根据知识库的内容选择最佳的推理路径。通过迭代检索和选择,逐步收集相关信息,构建完整的推理逻辑。
- 多智能体规划:在处理创造性问题时,引入多个智能体,每个智能体从不同角度进行推理和规划。通过多智能体的协作,生成更全面、更具创新性的解决方案。
- 多粒度检索:在多层异构知识图谱中进行多粒度检索,从整体文档到细粒度的知识单元,逐步细化检索范围。结合多层知识图谱的结构,提高知识检索的效率和准确性。
- 分阶段系统开发:根据任务复杂性,将RAG系统划分为不同等级(L1-L4),逐步提升系统能力。每个等级针对特定类型的问题,从简单的事实性问题到复杂的创造性问题,逐步增强系统的推理和生成能力。
PIKE-RAG的项目地址
- GitHub仓库:https://github.com/microsoft/PIKE-RAG
- arXiv技术论文:https://arxiv.org/pdf/2501.11551
PIKE-RAG的应用场景
- 法律领域:为法律专业人士提供法规解读、案例分析,助力精准的法律咨询与建议。
- 医疗领域:协助医生进行疾病诊断与治疗方案制定,提供基于专业知识的医疗建议。
- 半导体设计:支持工程师理解复杂物理原理,优化半导体设计与研发流程。
- 金融领域:应用于风险评估和市场预测,为投资决策提供数据支持及分析报告。
- 工业制造:优化生产流程与供应链管理,提升工业效率及质量控制。
常见问题
- PIKE-RAG如何提升生成回答的准确性?:通过专业知识提取和推理逻辑构建,PIKE-RAG能够为语言模型提供更精确的背景信息,从而提升生成回答的准确性。
- PIKE-RAG适用于哪些行业?:PIKE-RAG广泛应用于法律、医疗、半导体设计、金融和工业制造等多个行业,帮助专业人士解决复杂问题。
- 如何获取PIKE-RAG的技术支持?:用户可以通过访问其GitHub仓库和arXiv技术论文获取相关文档和支持信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。