LLaDA – 人大高瓴AI联合蚂蚁推出的扩散大语言模型
LLaDA(Large Language Diffusion with mAsking)是由中国人民大学高瓴AI学院的李崇轩、文继荣教授团队与蚂蚁集团合作开发的一款创新型大型语言模型。与传统的自回归模型(ARM)不同,LLaDA基于扩散模型框架,通过正向掩蔽与反向恢复过程来建模文本分布,利用Transformer作为掩蔽预测器,优化似然下界以实现文本生成。在预训练阶段,LLaDA使用了2.3万亿标记的数据,并通过监督微调(SFT)提升其指令遵循能力。其8B参数版本在多个基准测试中展现出与LLaMA3等顶尖模型相媲美的性能,表明扩散模型在语言生成领域的巨大潜力。
LLaDA是什么
LLaDA(Large Language Diffusion with mAsking)是一种新型大型语言模型,由中国人民大学高瓴AI学院的李崇轩、文继荣教授团队和蚂蚁集团联合推出。该模型基于扩散模型框架,区别于传统的自回归模型(ARM),通过正向掩蔽和反向恢复过程来建模文本的整体分布。LLaDA采用Transformer架构作为掩蔽预测器,利用优化似然下界的方法进行生成任务的实现。其预训练阶段使用了海量的数据,以提升模型在指令遵循方面的能力。LLaDA在可扩展性、上下文学习能力和指令执行能力等方面表现优异,成功解决了传统ARM的“反转诅咒”问题。
LLaDA的主要功能
- 高效文本生成:可以生成高质量、连贯的文本,适用于写作、对话和内容创作等多种场景。
- 强大的上下文学习能力:能够快速适应新任务,理解上下文信息。
- 指令执行能力:更好地理解并执行人类的指令,适合于多轮对话、问答和任务执行。
- 双向推理能力:在正向和反向推理任务中表现出色,能够有效解决传统自回归模型的“反转诅咒”,如在诗歌补全任务中。
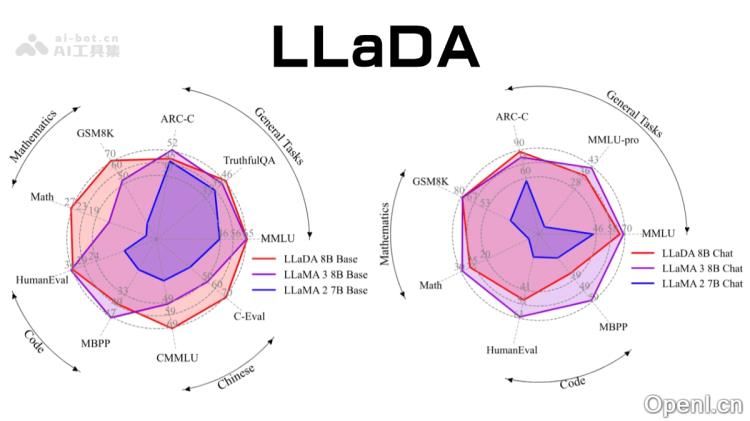
- 多领域适应性:在语言理解、数学、编程和中文理解等多个领域均表现优异,具有广泛的应用潜力。
LLaDA的技术原理
- 扩散模型框架:通过正向掩蔽过程逐步掩蔽文本标记,再通过反向恢复过程逐步恢复标记,从而建模文本分布。这一方法使得模型能够以非自回归的形式生成文本,克服了传统自回归模型的顺序生成限制。
- 掩蔽预测器:使用标准Transformer架构作为掩蔽预测器,输入部分掩蔽的文本序列,预测所有掩蔽的标记,从而捕捉双向依赖,而不仅仅是单向生成。
- 优化似然下界:通过优化似然下界进行模型训练,这一原理确保了在大规模数据和模型参数下的可扩展性和生成能力。
- 预训练与监督微调:结合预训练和监督微调(SFT),在预训练阶段利用大规模文本数据进行无监督学习,随后通过标注数据来提升模型的指令遵循能力。
- 灵活采样策略:在生成过程中,支持多种采样策略(如随机掩蔽、低置信度掩蔽、半自回归掩蔽等),在生成质量和效率之间取得平衡。
LLaDA的项目地址
- 项目官网:https://ml-gsai.github.io/LLaDA
- GitHub仓库:https://github.com/ML-GSAI/LLaDA
- arXiv技术论文:https://arxiv.org/pdf/2502.09992
LLaDA的应用场景
- 多轮对话:可用于智能客服和机器人,支持流畅的多轮交互。
- 文本生成:适合于创作辅助和文案生成,能够输出高质量文本。
- 代码生成:为开发者提供代码片段或修复建议,提升编程效率。
- 数学推理:解决数学问题并提供解题步骤,适用于教育领域。
- 语言翻译:实现跨语言翻译,促进文化交流。
常见问题
- 如何使用LLaDA?:用户可以通过项目官网或GitHub获取相关文档与接口说明,按照指引进行使用。
- LLaDA的性能如何?:LLaDA在多项基准测试中表现突出,尤其在文本生成和指令遵循能力方面与顶尖模型相当。
- LLaDA适合哪些行业?:LLaDA广泛适用于客服、教育、内容创作等多个行业,能够提升工作效率。
- 如何获取LLaDA的更新?:用户可以关注项目的GitHub仓库,获取最新的更新和发布信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。