AgentRefine – 北京邮电大合美团推出的智能体合成框架
AgentRefine是一种由北京邮电大学与美团联合开发的智能体合成框架,旨在通过“精炼调整”(Refinement Tuning)技术增强基于大型语言模型(LLM)的智能体在各种任务中的适应能力。该框架允许智能体通过观察其行为轨迹来纠正错误,从而实现自我优化。
AgentRefine是什么
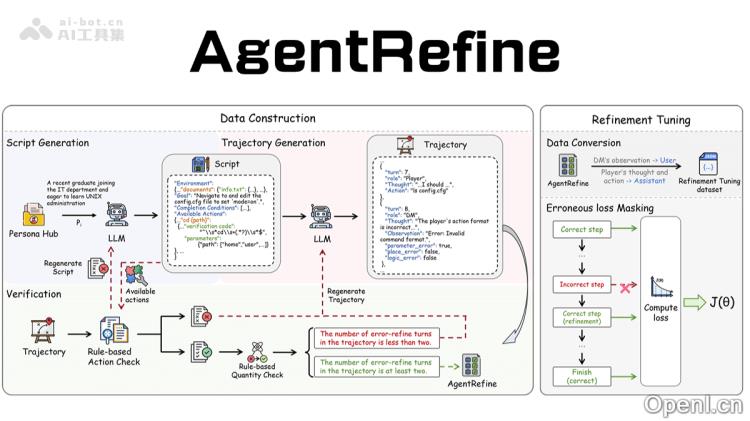
AgentRefine是一个创新的智能体合成框架,由北京邮电大学和美团共同研发,旨在通过“精炼调整”技术提升基于大型语言模型的智能体在多样化任务中的泛化能力。智能体能够通过对自身行为轨迹的观察来学习并纠正错误,进而实现自我优化。研究团队受到桌面角色扮演游戏(TRPG)的启发,设计了一套包括脚本生成、轨迹生成及验证的数据构建流程。
AgentRefine的主要功能
- 错误纠正与自我优化:AgentRefine通过观察轨迹,让智能体学习如何纠正错误,类似于人类在面对问题时的反思过程,从而使智能体更灵活地适应新环境和任务。
- 多样化环境与任务集成:该框架融合了多种不同的环境和任务,促使智能体在复杂场景中灵活调整其策略。
- 增强鲁棒性:AgentRefine在环境扰动下展现出更强的鲁棒性,即便在任务描述或环境设置发生微小变化时,仍能保持良好的性能。
- 推理过程多样化:AgentRefine能够在推理过程中生成多种思路,依赖于记忆中的固定模式,并根据环境反馈动态调整决策路径。
AgentRefine的技术原理
- 自我精炼能力:AgentRefine的核心理念是使智能体通过轨迹观察来纠正自身错误。框架通过模拟多轮交互,让模型在产生错误行为后,根据环境反馈进行自我修正,从而避免重复固定模式,探索出正确的行动序列。
- 数据合成与验证:该框架通过生成多轮交互数据,利用验证器检测生成内容中的格式或逻辑错误。错误的交互记录下来,并提示模型根据观察结果进行修正,最终形成经过自我精炼的数据集。
- 鲁棒性与推理多样化:AgentRefine在面对环境扰动时表现出卓越的鲁棒性,能够在任务描述或环境设置轻微变化时依然保持良好表现。同时,框架能生成多样化的推理路径,进一步提升智能体的泛化能力。
AgentRefine的项目地址
- 项目官网:https://agentrefine.github.io/
- Github仓库:https://github.com/Fu-Dayuan/AgentRefine
- arXiv技术论文:https://arxiv.org/pdf/2501.01702
AgentRefine的应用场景
- 复杂任务的自动化决策:AgentRefine能够应用于复杂环境中的多轮决策任务,如自动驾驶、机器人导航和智能客服等。
- 游戏AI与虚拟环境:在游戏AI和虚拟环境中,AgentRefine通过自我优化提升智能体的决策质量和多样性。
- 代码生成与优化:在代码生成领域,AgentRefine可以生成初步代码,并通过自我反思机制识别错误和不足,进行迭代优化,以生成高质量的代码。
- 自然语言处理任务:在自然语言处理领域,AgentRefine能够用于文本生成和对话系统,通过自我反思机制优化内容,从而提高文章质量。
- 科学研究和模拟环境:在需要模拟复杂环境的科学研究中,AgentRefine通过自我纠正和泛化能力,更好地适应动态变化的环境。
常见问题
- AgentRefine适合哪些类型的任务? AgentRefine适用于需要多轮决策和自我反思的复杂任务,如自动驾驶、智能客服、游戏AI等。
- 如何提升AgentRefine的性能? 通过丰富的训练数据和环境反馈,可以帮助AgentRefine实现更好的自我优化和性能提升。
- AgentRefine的开发是否开源? 是的,AgentRefine的相关代码和文档都可以在其GitHub仓库中找到。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。