DeepGEMM – DeepSeek 开源的 FP8 通用矩阵乘法库
DeepGEMM是什么
DeepGEMM是由DeepSeek开发的开源库,专为高效和简洁的FP8矩阵乘法(GEMM)而设计。目前,该库仅兼容NVIDIA Hopper架构的张量核心。DeepGEMM不仅支持普通的GEMM操作,还支持混合专家(MoE)模型中的分组矩阵乘法。它基于即时编译(JIT)技术,允许在运行时进行动态优化,无需事先进行编译。通过细粒度缩放和CUDA核心的双级累加机制,DeepGEMM有效解决了FP8精度不足的问题,并利用Hopper的Tensor Memory Accelerator(TMA)特性大幅提升数据传输效率。其核心代码简约,仅约300行,便于学习和优化,且在多种矩阵形状下的性能达到或超过专家级优化库的水平。

DeepGEMM的主要功能
- 高效FP8矩阵乘法(GEMM):专为FP8(8位浮点数)矩阵乘法优化的库,采用细粒度缩放技术,显著提升计算性能与精度。
- 支持普通和分组GEMM:
- 普通GEMM:适合常规矩阵乘法操作。
- 分组GEMM:优化混合专家(MoE)模型中的分组矩阵乘法,支持连续布局和掩码布局,提升多专家共享形状的计算效率。
- 即时编译(JIT)设计:所有内核在运行时动态编译,避免安装时编译,根据矩阵形状和块大小等参数进行优化,提升性能并节约寄存器。
- Hopper架构优化:专为NVIDIA Hopper架构设计,充分利用TMA特性,包括加载、存储、多播和描述符预取,大幅提高数据传输效率。
- 细粒度缩放和双级累加:通过细粒度缩放技术和CUDA核心的双级累加机制,解决FP8计算的精度问题,将FP8结果提升至更高精度格式(如BF16),确保计算精度。
- 轻量级设计:核心代码简洁,易于理解和扩展,避免复杂的模板或代数结构依赖,降低学习和优化的门槛。
产品官网
DeepGEMM的性能表现
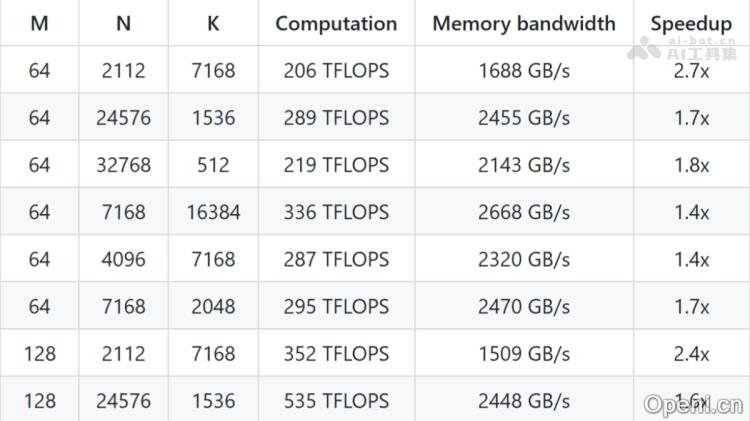
- 普通GEMM(非分组)性能
- 最高加速比:在特定矩阵形状下,DeepGEMM能够实现高达2.7倍的加速,大幅提升矩阵乘法效率。
- 计算性能:在大规模矩阵计算中,DeepGEMM的计算性能超过1000 TFLOPS,接近Hopper架构GPU的理论峰值。
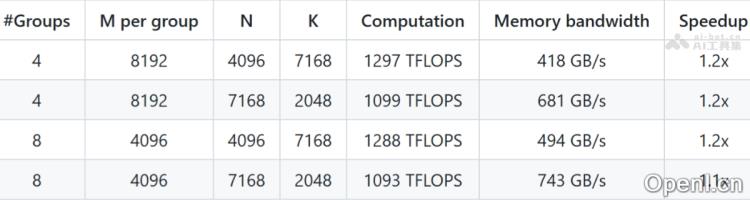
- 分组GEMM(MoE模型)性能
- 加速比:在分组GEMM中,DeepGEMM的加速比为1.1至1.2倍,显著提升MoE模型的训练和推理效率。
- 内存带宽优化:利用TMA特性,DeepGEMM在内存带宽的利用上表现卓越,接近硬件性能极限。
- 连续布局(Contiguous Layout)
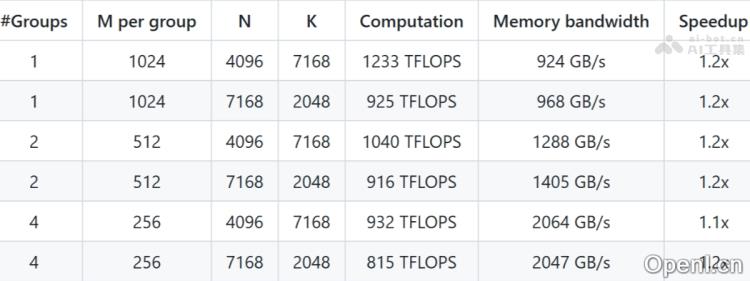
- 掩码布局(Masked Layout)
DeepGEMM的系统要求
- 硬件要求:
- GPU架构:必须支持NVIDIA Hopper架构,具体要求为支持sm_90a的GPU。推荐使用H800或H100等专为FP8计算和Tensor Core优化的Hopper架构GPU。
- CUDA兼容性:需支持CUDA 12.3或更高版本,推荐使用CUDA 12.8或更高版本以获得最佳性能。
- 软件要求:
- 操作系统推荐:建议使用Linux操作系统(如Ubuntu、CentOS等),以便于CUDA和PyTorch的更好支持。
- Python版本:Python 3.8或更高版本。
- CUDA工具包:CUDA 12.3或更高版本。CUDA版本需与GPU架构相匹配,推荐使用12.8或更高版本以充分发挥Hopper架构的优势。
- PyTorch:PyTorch 2.1或更高版本。
- CUTLASS库:CUTLASS 3.6或更高版本。
- 其他要求:
- 标准编译工具(如gcc、make等)。
- torch.utils.cpp_extension模块,用于CUDA扩展。
DeepGEMM的应用场景
- 大规模AI模型推理:加速高维矩阵乘法,提升推理速度。
- 混合专家(MoE)模型:优化分组矩阵乘法,增强计算效率。
- 低精度计算:通过细粒度缩放解决FP8精度问题,确保高精度输出。
- 高性能计算:基于Hopper架构特性,提升矩阵运算效率。
- 深度学习框架优化:作为底层优化库,加速模型的训练和推理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。