Wan2.1 – 阿里开源的AI视频生成大模型
Wan2.1是什么
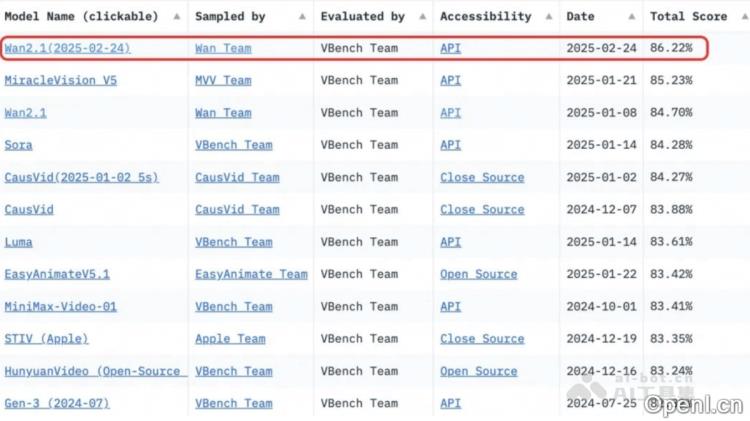
Wan2.1是阿里云推出的一款开源AI视频生成大模型,拥有强大的视觉创作能力。该模型支持文本生成视频和图像生成视频两大任务,提供两种不同尺寸的模型:14B参数的专业版擅长于复杂的生成和物理建模,性能优异;而1.3B参数的极速版则能够在消费级显卡上流畅运行,显存需求低,特别适合二次开发和学术研究。Wan2.1模型基于因果3D VAE和视频Diffusion Transformer架构,能够高效进行时空压缩与长时程依赖建模。在权威评测集Vbench中,14B版本以总分86.22%的成绩显著超越了包括Sora、Luma和Pika在内的多个国内外模型,稳居第一。Wan2.1采用Apache 2.0协议开源,支持多种主流框架,已在GitHub、HuggingFace及魔搭社区上线,为开发者提供了便捷的使用与部署环境。

Wan2.1的主要功能
- 文本生成视频:根据用户输入的文本描述生成相应的视频内容,支持中英文长文本指令,精准还原场景切换与角色互动。
- 图像生成视频:以图像为基础生成动态视频,适合将静态图像转化为生动视频的需求,提供更高的创作控制力。
- 复杂生成:稳定呈现人物或物体的复杂,如旋转、跳跃和转身,支持高级运镜控制。
- 物理规律模拟:精准模拟碰撞、反弹和切割等真实物理场景,生成符合物理法则的视频内容。
- 多风格生成:支持多样化的视频风格与质感,满足不同的创作需求,同时支持多种长宽比的视频输出。
- 文字特效生成:具备中文文字生成能力,支持中英文文字特效,为视频增添视觉吸引力。
Wan2.1的技术原理
- 因果3D VAE架构:Wan2.1自研的因果3D VAE架构专为视频生成而设计,通过编码器将输入数据压缩为潜在空间表示,再通过解码器重建输出。在视频生成中,3D VAE能有效处理时空信息,结合因果性约束,确保生成视频的连贯性和逻辑性。
- 视频Diffusion Transformer架构:基于主流的扩散模型和Transformer架构,扩散模型通过逐步去噪生成数据,而Transformer则利用自注意力机制捕捉长时程依赖关系。
- 模型训练与推理优化:
- 训练阶段:采用DP(数据并行)与FSDP(全Sharded数据并行)相结合的分布式策略,加速文本与视频编码模块的训练。对于扩散模块,使用DP、FSDP、RingAttention和Ulysses混合的并行策略,进一步提升训练效率。
- 推理阶段:通过CP(通道并行)进行分布式加速,减少单个视频生成的延迟。针对大模型,应用模型切分技术,进一步优化推理效率。
Wan2.1的性能优势
- 卓越的生成质量:在Vbench评测中,14B参数的专业版本总分达到86.22%,显著超越其他国内外模型(如Sora、Luma、Pika等),稳居榜首。
- 支持消费级GPU:1.3B参数的极速版仅需8.2GB显存即可生成480P视频,兼容几乎所有消费级GPU,约在4分钟内在RTX 4090上生成5秒的480P视频。
- 多功能支持:涵盖文本生成视频、图像生成视频、视频编辑、文本生成图像及视频生成音频等多种任务,同时具备视觉特效与文字渲染能力,满足多样化的创作需求。
- 高效的数据处理与架构优化:基于自研的因果3D VAE和优化训练策略,支持任意长度视频的高效编解码,显著降低推理内存占用,提升训练与推理效率。
Wan2.1的项目地址
- 项目官网:https://wanxai.com
- GitHub仓库:https://github.com/Wan-Video/Wan2.1
- HuggingFace模型库:https://huggingface.co/Wan-AI
Wan2.1的效果展示
- 复杂:擅长生成涵盖广泛肢体动作、复杂旋转、动态场景切换以及流畅镜头的逼真视频。

- 物理模拟:能够生成准确模拟现实世界物理规律和逼真物体交互的视频。

- 影院级别画质:提供如同电影般的视觉效果,拥有丰富的纹理与多样化的风格化特效。

- 可控编辑:具备通用编辑模型,可以通过图像或视频参考进行精准的编辑。

Wan2.1的应用场景
- 影视制作与特效:能够生成复杂的动作场景、特效镜头或虚拟角色动画,从而显著降低拍摄成本与时间。
- 广告与营销:快速生成创意广告视频,依据产品特点或品牌调性定制个性化视频内容。
- 教育与培训:生成教育视频,如科学实验演示、历史场景重现或语言学习视频,以增强学习体验。
- 游戏开发:用于生成游戏内部的动画、过场视频或虚拟角色动作,提升游戏的视觉效果与沉浸感。
- 个人创作与社交媒体:帮助创作者迅速生成创意视频,适用于社交媒体分享、Vlog制作或个人项目展示。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。