而实现语言模型实体层级的对比学习
原标题:如何让大模型感知知识图谱知识?蚂蚁联合实验室:利用多词元并行预测给它“上课”
文章来源:量子位
内容字数:4720字
蚂蚁AI团队:赋予大模型知识图谱感知能力
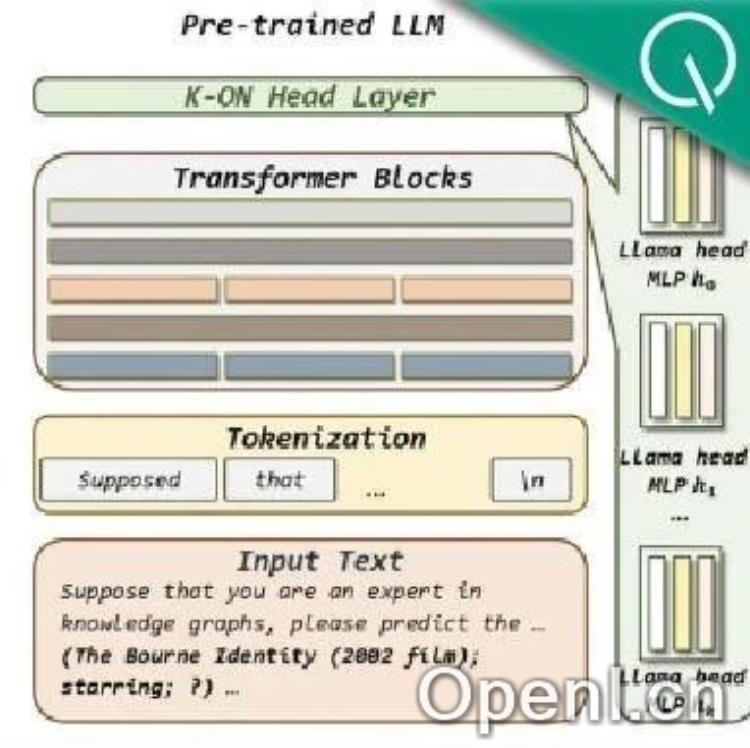
蚂蚁集团联合实验室在AAAI 2025会议上发表论文,提出了一种名为K-ON的多词元并行预测方法,有效地解决了大语言模型在处理知识图谱数据时存在的粒度不匹配问题。该方法通过让大模型能够感知知识图谱中的实体知识,显著提升了知识图谱补全任务的性能。
1. 问题:大模型与知识图谱的粒度不匹配
大语言模型通常以预测下一个词元为目标进行训练,这与许多自然语言处理任务相契合。然而,知识图谱中的实体往往需要多个词元才能准确描述,导致两者之间存在粒度不匹配。直接使用大模型处理知识图谱实体,可能导致模型生成不存在的实体,或需要复杂的处理步骤。
2. K-ON方法:多词元并行预测与实体对比学习
为了解决上述问题,蚂蚁团队提出了K-ON方法。该方法的核心思想是采用多词元并行预测机制,一次性生成对所有候选实体的评估结果。具体来说,K-ON包含以下步骤:
将知识图谱补全问题以文本指令形式输入大模型。
将大模型Transformer模块的输出输入到K-ON模块,该模块由多个MLP构成,对应于要预测实体的不同位置的词元。
使用Conditional Transformer混合不同位置的信息,考虑词元间的顺序依赖性。
利用低秩适应技术(LoRA)将原大模型评分层构造为K个新的评分层,将输出转换为对实体K个连续词元的概率预测分布。
从概率预测分布中抽取各实体词元的概率值,一次性评估所有候选实体的分数。
此外,K-ON还利用实体层级的对比学习,通过比较正负样本实体的分数,让大模型学习知识图谱中实体的分布。同时,为了使多词元并行预测结果与单步连续预测结果相接近,K-ON还引入了单步预测损失进行优化。
3. 实验结果:高效、低成本、高性能
实验结果表明,K-ON在多个数据集上的知识图谱补全任务中均优于现有方法,包括基于大模型的方法和多模态方法。K-ON在效率和成本方面也具有显著优势,其推理时间和训练时间受K值影响不大,即使处理上千个负样本实体,对效率的影响也微乎其微。
4. 总结
蚂蚁团队提出的K-ON方法,通过多词元并行预测和实体层级的对比学习,有效地赋予了大语言模型感知知识图谱知识的能力。该方法在知识图谱相关任务上具有显著的性能优势,并且具有更高的训练和推理效率。这为大语言模型在知识图谱领域的应用提供了新的思路和方法。
蚂蚁集团在AAAI 2025共有18篇论文被收录,其中3篇为Oral,展示了其在人工智能领域的雄厚实力。
联系作者
文章来源:量子位
作者微信:
作者简介:追踪人工智能新趋势,关注科技行业新突破
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。