为大模型在长序列任务中的应用带来了新的可能性。
原标题:稀疏注意力再添一员,华为诺亚推出高效选择注意力架构ESA
文章来源:智猩猩GenAI
内容字数:6412字
华为诺亚方舟实验室提出高效选择性注意力算法ESA
本文介绍了华为诺亚方舟实验室提出的高效选择性注意力算法ESA (Efficient Selective Attention),该算法旨在解决大语言模型(LLMs)处理长文本序列时的效率瓶颈。ESA通过创新性的稀疏注意力机制,在显著降低计算复杂度的同时,保持了模型的准确性,实现了上下文长度的有效扩展。
1. 长序列处理的挑战
随着序列长度的增加,注意力计算的复杂度呈平方级增长,这使得高效且准确的长序列推理成为一大挑战。现有方法试图通过短序列训练成果外推到长序列,但面临着OOD(out-of-distribution)问题和计算量迅速增大的难题。选择性注意力(Selective Attention)利用注意力矩阵的稀疏性,选择部分token进行计算,但token粒度选择会引入巨大的计算开销。
2. ESA算法的核心思想
ESA算法的核心在于平衡选择性注意力方法中的灵活性与效率。它通过以下两个核心步骤实现高效的长序列处理:
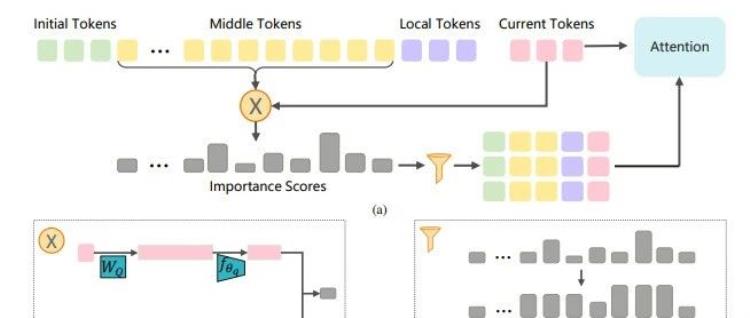
- 高效选择:ESA采用基于query感知的token粒度选择机制。通过对query和key进行低维压缩(约3.2%),计算token的重要性分数,并考虑周围token的影响(邻距影响力),避免仅选择top-ranked token导致的性能下降。
- 注意力计算:在选择关键token后,ESA使用被选中token的完整query和key进行注意力计算,而非对所有前序token进行计算,从而大幅降低复杂度。
ESA的具体实现包括将输入序列的token分为四部分:全局注意力和局部注意力。初始token和ESA选择的topk中间token拼接起来计算全局注意力,局部token用于计算窗口注意力,两部分注意力融合计算最终的注意力。ESA采用chunked-prefill缓存key和value,动态选择关键token。
3. ESA算法的创新点
ESA的主要创新在于其基于token的细粒度选择性注意力机制。它能够在prefilling和decoding阶段动态选择最关键的少量token,而不是固定block选择或永久丢弃不重要的token。通过低维压缩query和key,将注意力计算复杂度从平方级降低到线性级。此外,ESA引入了邻距影响力,考虑周围token的影响,进一步提升了模型性能。
4. 实验结果与分析
论文在Longbench、InfiniteBench、NeedleBench等公开的长序列基准测试中验证了ESA的性能。结果表明,ESA在高倍外推场景下优于全注意力算法,尤其在multi needles检索场景下表现突出。实验还分析了邻距影响力超参数的影响,以及将所有head整合计算重要性分数对算法的影响。
5. 总结与展望
ESA有效平衡了长序列外推场景下的选择性注意力中的灵活性和计算效率,无需模型参数增量微调即可扩展上下文长度。ESA通过选择固定数量的最重要token计算注意力,并利用注意力矩阵的稀疏性,在输入序列足够长时,通过低维压缩query和key有效降低计算复杂度。未来的研究方向包括探索更准确高效的选择重要token的方法,以及软硬件协同的高效外推方案。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。