原标题:DeepSeek 开源第二天:DeepEP,AI 训练和推理的超级 “加速器”
文章来源:小夏聊AIGC
内容字数:1469字
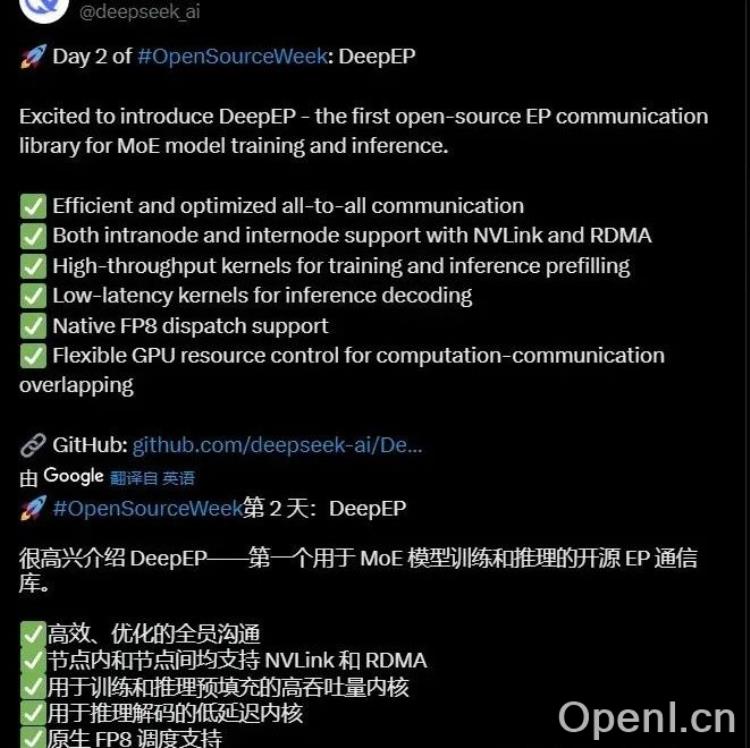
DeepSeek开源再放大招:DeepEP赋能MoE模型,加速AI发展
继昨日开源专为Hopper GPU打造的FlashMLA后,DeepSeek今日再次带来惊喜,开源了DeepEP——一款用于混合专家(MoE)模型训练和推理的开源EP通信库。这一举动无疑将进一步推动AI领域的技术发展,为研究者和开发者提供强有力的工具。
什么是DeepEP?
简单来说,DeepEP就像一个为MoE模型量身打造的“超级加速器”,它能够显著提升MoE模型的训练和推理效率。MoE模型因其强大的参数扩展能力而备受关注,但其训练和推理过程也面临着巨大的通信挑战。DeepEP正是为了解决这一难题而诞生的。
DeepEP的核心优势
DeepEP拥有诸多令人瞩目的特性,使其在MoE模型的通信优化方面脱颖而出:
- 高效的全员沟通: DeepEP对节点内和节点间的通信进行了优化,支持NVLink和RDMA,如同为模型搭建了一条高速信息公路,确保数据传输的高效性和稳定性。
- 高吞吐量内核: 预填充功能如同为模型“加满油”,让训练和推理过程能够快速启动,避免了等待时间的浪费。
- 低延迟内核: 在推理解码阶段,低延迟内核保证了解码速度,避免卡顿,提升用户体验。
- 原生FP8调度支持: 支持原生FP8调度,如同为模型配备了一个智能调度员,能够高效地分配计算资源,进一步提升效率。
- 灵活的GPU资源控制: DeepEP能够实现计算-通信重叠,如同一个高效的管家,合理分配GPU资源,让计算和通信同时进行,最大限度地提高效率。
DeepEP的意义
DeepEP的开源,为MoE模型的训练和推理提供了强大的工具支持,降低了研究和应用的门槛。这将加速MoE模型在各个领域的应用,推动AI技术的发展和创新。对于开发者而言,DeepEP提供了高效、易用的通信库,能够帮助他们更快速地开发和部署MoE模型应用。
未来展望
DeepSeek持续的开源贡献,展现了其推动AI技术进步的决心。FlashMLA和DeepEP的相继开源,预示着未来AI领域将涌现更多令人兴奋的创新和突破。我们期待DeepSeek未来能够带来更多优秀的开源项目,为AI社区贡献力量。
感兴趣的读者可以访问GitHub地址:https://github.com/deepseek-ai/DeepEP了解更多信息。
联系作者
文章来源:小夏聊AIGC
作者微信:
作者简介:专注于人工智能生成内容的前沿信息与技术分享。我们提供AI生成艺术、文本、音乐、视频等领域的最新动态与应用案例。每日新闻速递、技术解读、行业分析、专家观点和创意展示。期待与您一起探索AI的无限潜力。欢迎关注并分享您的AI作品或宝贵意见。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。