xAR – 字节联合霍普金斯大学推出的自回归视觉生成框架
xAR是什么
xAR 是一款由字节跳动与约翰·霍普金斯大学合作开发的先进自回归视觉生成框架。该框架采用“下一个X预测”(Next-X Prediction)和“噪声上下文学习”(Noisy Context Learning)技术,有效解决了传统自回归模型在视觉生成中存在的信息密度不足及累积误差的问题。
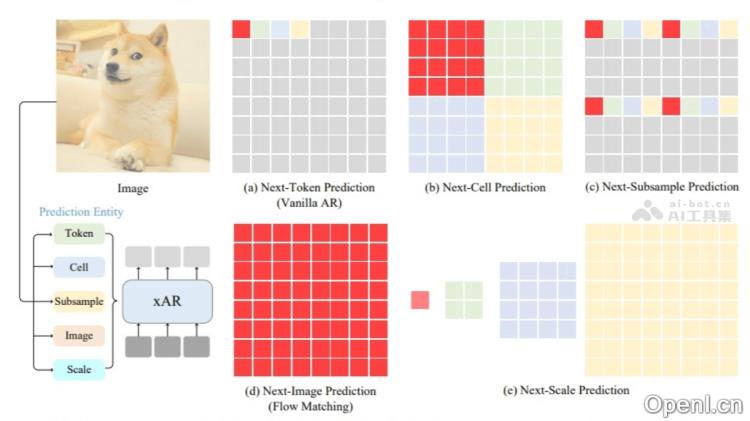
xAR的主要功能
- 下一个X预测(Next-X Prediction):该功能超越了传统的“下一个标记预测”,使模型能够预测更复杂的视觉实体(例如图像块、单元、子采样和整体图像),从而捕捉到更丰富的语义信息。
- 噪声上下文学习(Noisy Context Learning):通过在训练过程中引入噪声,该技术增强了模型对误差的鲁棒性,显著缓解了累积误差问题。
- 卓越的生成性能:在ImageNet数据集上,xAR模型在推理速度和生成质量上均优于现有技术,如DiT及其他扩散模型。
- 灵活的预测单元:支持多种预测单元设计(如单元、子采样和多尺度预测等),适应不同的视觉生成任务。
xAR的技术原理
- 流匹配(Flow Matching):xAR通过流匹配方法将离散标记分类问题转化为连续实体回归问题,具体过程包括:
- 模型通过插值和噪声注入生成带噪声的输入。
- 在每个自回归步骤中,模型预测从噪声分布到目标分布的方向流(Velocity),从而逐步优化生成结果。
- 推理策略:在推理阶段,xAR采用自回归的方式逐步生成图像:
- 首先从高斯噪声中预测初始单元(例如8×8的图像块)。
- 基于已生成的单元,模型逐步生成下一个单元,直至完成整个图像的生成。
- 实验结果:xAR在ImageNet-256和ImageNet-512基准测试中显示出显著的性能提升:
- xAR-B(1.72亿参数)模型在推理速度上比DiT-XL(6.75亿参数)快20倍,同时在弗雷歇生成距离(FID)上达到1.72,超越了现有的扩散模型和自回归模型。
- xAR-H(11亿参数)模型在ImageNet-256上达到了1.24的FID,创造了新的最优记录,并且不依赖于视觉基础模型(如DINOv2)或高级引导区间采样。
xAR的项目地址
xAR的应用场景
- 艺术创作:艺术家可以利用xAR生成创意图像,作为创作灵感的来源或直接用于艺术作品的创作。xAR能够生成丰富细节和多样风格的图像,满足不同分辨率和风格的需求。
- 虚拟场景生成:在游戏开发和虚拟现实(VR)领域,xAR可以迅速生成逼真的虚拟场景,包括自然风光、城市环境和虚拟角色等,极大提升用户体验。
- 老照片修复:通过生成高质量的图像内容,xAR能够修复老照片中的损坏部分,恢复其原始细节和色彩。
- 视频内容生成:xAR可用于生成视频中特定的场景或对象,应用于视频特效制作、动画生成及视频编辑等领域。
- 数据增强:通过生成多样化的图像,xAR能够扩展训练数据集,提升模型的泛化能力和鲁棒性。
常见问题
- xAR的使用门槛高吗?:xAR设计上考虑了用户友好性,提供了易于使用的界面,适合不同技能水平的用户。
- 生成的图像质量如何?:xAR在多个基准测试中展现了优异的生成质量,其生成的图像细节丰富,风格多样。
- 是否支持多种平台?:xAR可以在多种计算环境中运行,适用于研究、开发及商业应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。