MultiQueryRetriever是 LangChain 提供的一种增强检索工具,能够通过生成多个查询变体提高召回率,解决单一查询匹配度不足的问题。它适用于模糊查询、开放域问答、长文档检索等场景
原标题:LangChain实战 | MultiQueryRetriever 让 RAG 更懂你的问题
文章来源:AI取经路
内容字数:6554字
LangChain中的MultiQueryRetriever:提升检索召回率的利器
在信息检索领域,准确高效地获取相关信息至关重要。然而,传统的检索方法往往受限于单一查询的表达能力,容易遗漏重要的信息,导致召回率低下。为了解决这个问题,LangChain提供了一种强大的检索增强工具——MultiQueryRetriever,它能够通过生成多个查询变体来显著提升检索的全面性和准确性。
什么是MultiQueryRetriever?
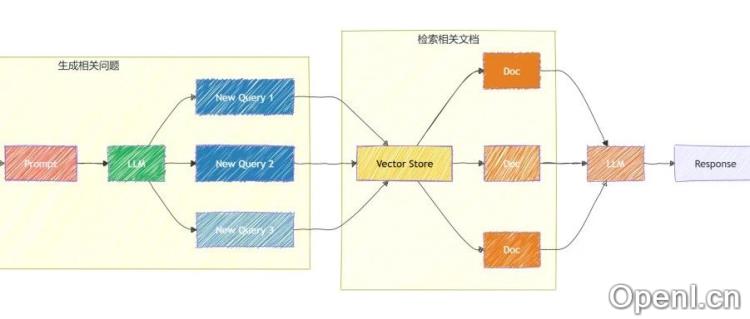
MultiQueryRetriever的核心思想是克服单一查询的局限性。它并非依赖于单一查询检索到的文档集来生成最终结果,而是利用大型语言模型(LLM)自动生成多个表达相同信息需求的查询变体。这些变体以不同的方式表达同一问题,从而确保检索涵盖更广泛的相关内容。这在处理模糊、不精确或用户表达方式多样化的查询时尤为有效,能够有效提高检索的召回率和鲁棒性。
MultiQueryRetriever的工作原理
传统检索的局限性
传统的基于嵌入向量的检索方法,通常将查询文本转换为固定向量或关键词集合进行搜索。这种方法存在以下不足:首先,不同用户可能使用不同的词语表达同一问题,导致查询表述不统一;其次,如果查询与索引库中的向量或关键词不精确匹配,则可能无法检索到相关文档,导致召回率低;最后,这种方法难以处理语义上的变体,可能错过与查询语义相关但表达方式不同的文档。
MultiQueryRetriever的核心机制
MultiQueryRetriever巧妙地解决了这些问题。它的工作流程主要包括三个步骤:首先,利用LLM(例如OpenAI GPT)根据用户输入生成多个查询变体;其次,将这些变体分别提交给底层的检索器(Retriever),获取各自的相关文档;最后,对所有检索结果进行去重和排序,以确保最终返回的文档质量更高,并兼顾全面性和准确性。
代码示例与执行过程
以下是一个简单的代码示例,演示如何使用MultiQueryRetriever进行检索:(由于篇幅限制,此处仅提供代码框架,具体的代码实现需要根据实际环境和库版本进行调整。)
首先,加载文档并进行分块处理;然后,创建基于OpenAIEmbeddings的向量数据库;接着,创建MultiQueryRetriever实例,并指定LLM;最后,利用创建好的检索器和LLM构建检索链,并进行查询。
在执行过程中,MultiQueryRetriever会根据用户问题生成多个查询变体,然后分别进行检索,最后合并并去重结果,最终返回高质量的检索结果。
适用场景
MultiQueryRetriever适用于多种场景,能够显著提升检索效果:
模糊查询的搜索场景
当用户输入的查询过于简短或表述不清时,MultiQueryRetriever可以生成更详细、更全面的查询变体,例如将“AI 未来”扩展为“人工智能的未来发展趋势”、“AI技术未来发展方向”等,从而提高召回率。
开放域问答
在开放域问答中,用户的问题可能有多种表达方式。MultiQueryRetriever能够生成多个查询变体,确保检索系统涵盖不同角度的答案,提升问答质量。
长文档检索
对于长文档,MultiQueryRetriever可以帮助拆解查询,并从多个角度进行搜索,从而提高检索的准确性和全面性。
总结
MultiQueryRetriever是LangChain提供的一个强大的检索增强工具,它通过生成多个查询变体来提高检索召回率,解决了单一查询匹配度不足的问题。其在模糊查询、开放域问答和长文档检索等场景中具有显著的优势,能够有效提升RAG系统的性能和效率。结合其他检索增强工具,可以构建更强大的信息检索系统,为用户提供更精准、更全面的信息服务。
联系作者
文章来源:AI取经路
作者微信:
作者简介:踏上取经路,比抵达灵山更重要! AI技术、 AI知识 、 AI应用 、 人工智能 、 大语言模型
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。