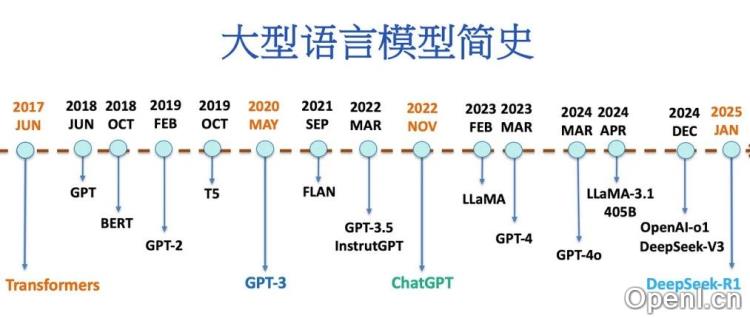
本文回顾LLM的发展历程,以2017年具有性意义的Transformer架构为起点。
原标题:最新「大语言模型简史」整理!从Transformer(2017)到DeepSeek-R1(2025)
文章来源:智猩猩GenAI
内容字数:18150字
大型语言模型简史:从Transformer (2017)到DeepSeek-R1 (2025)
本文回顾了大型语言模型(LLMs)从2017年Transformer架构诞生到2025年DeepSeek-R1的发展历程。2025年初,我国推出的DeepSeek-R1引发了AI领域的巨大变革,本文将详细阐述LLMs的演进。
1. 语言模型概述
1.1 大型语言模型 (LLMs) 是语言模型 (LMs) 的一个子集,其规模显著更大,通常包含数十亿个参数,从而在广泛的任务中表现出卓越的性能。“LLM”一词在GPT-3发布后才广泛使用。
1.2 大多数LLMs以自回归方式操作,根据前面的文本预测下一个字的概率分布。LLM通过解码算法确定下一个输出的字,例如贪婪搜索或随机采样。
1.3 LLMs的自回归特性使其能够基于前文提供的上下文逐词生成文本,如同“文字接龙”游戏,推动了创意写作、对话式AI等应用的发展。
2. Transformer (2017)
2.1 Vaswani等人于2017年提出的Transformer架构,解决了早期模型如RNN和LSTM在长程依赖性和顺序处理方面的困难。其关键创新包括自注意力机制、多头注意力、前馈网络、层归一化和位置编码。这些创新使得在大型数据集上训练大规模模型成为可能,并提高了全局上下文理解。
3. 预训练Transformer模型时代 (2018–2020)
3.1 BERT (2018) 采用双向训练方法,同时从两个方向捕获上下文,在文本分类、命名实体识别等任务中表现出色。其关键创新包括掩码语言建模和下一句预测。
3.2 GPT系列 (2018–2020) 专注于通过自回归预训练实现生成能力。GPT-2展示了令人印象深刻的零样本能力,而GPT-3则凭借1750亿参数,突破了大规模预训练的界限,展示了显著的少样本和零样本学习能力。
3.3 GPT模型的引入,特别是GPT-3,标志着AI的一个变革时代,展示了自回归架构和生成能力的强大功能,证明了规模、数据和计算在实现最先进结果中的重要性。
4. 后训练对齐:弥合AI与人类价值观之间的差距 (2021–2022)
4.1 监督微调 (SFT) 和基于人类反馈的强化学习 (RLHF) 等技术被用来改善与人类意图的一致性并减少幻觉。
4.2 RLHF 通过根据质量对模型生成的输出进行排名,创建一个偏好数据集,用于训练奖励模型,指导LLM的微调,从而生成更符合人类偏好和期望的输出。
4.3 ChatGPT (2022) 基于GPT-3.5和InstructGPT,擅长维持对话的上下文和连贯性,生成有用、诚实和无害的响应。
5. 多模态模型:连接文本、图像及其他 (2023–2024)
5.1 GPT-4V 将GPT-4的语言能力与计算机视觉相结合,可以解释图像、生成标题等。
5.2 GPT-4o 整合了音频和视频输入,在一个统一的表示空间中运行,可以转录音频、描述视频或将文本合成音频。
6. 开源和开放权重模型 (2023–2024)
开放权重模型和开源模型的出现,使先进AI技术的访问更加化,促进了社区驱动的创新。
7. 推理模型:从“系统1”到“系统2”思维的转变 (2024)
7.1 OpenAI-o1 和 OpenAI-o3 采用了“长链思维”,能够将复杂问题分解为更小的部分,批判性地评估其解决方案,并在复杂数学和编程任务中树立了新的标杆。
8. 成本高效的推理模型:DeepSeek-R1 (2025)
8.1 DeepSeek-V3 (2024-12) 采用专家混合(MoE)架构,开发成本显著降低,性能与顶级解决方案相媲美。
8.2 DeepSeek-R1-Zero 和 DeepSeek-R1 (2025-01) 利用先进的强化学习技术,在没有巨额计算费用的情况下实现了高性能推理,其成本相比竞争对手低20到50倍。
8.3 DeepSeek-R1的引入挑战了AI领域的既定规范,使先进LLMs得以“普及化”,并促进了一个更具竞争力的生态系统。
9. 结论
从Transformer到DeepSeek-R1,LLMs的演变标志着人工智能领域的一个性篇章。LLMs正逐步演变为多功能、多模态的推理系统,推动人工智能朝着更加包容和影响力深远的方向迈进。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章

全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。